requests是一個python模擬網路請求的套件
基本用法為
import requests
r=requests.get(url)
r就會得到response物件
- 可以使用dir(r) 轉成字典型態看出裡面的property
- 也可以使用help(r) 打開使用手冊
response 物件
response物件能夠告訴我們很多連線資訊
如
連線相關
response.status_code(HTTPcode 200系列正常、300系列重導、400系列錯誤 ….)

*response物件若介於200-400之間,會被boolean轉型為true
*最好還是使用status_code檢查,才能精準了解連線情況,比如204(無內容)與304(無修改) 原則上與200(成功連線) 有一些不同
response.ok (是否連線成功 , aka 200系列)
內容相關
回傳的訊息內容,也就是負載(payload),可以用response的方法與property去查看
note:payload通常指實際傳輸的信息
response.content 可以用二進位內容查看payload
response.text 則可以用UTF-8 的格式查看文字內容
response.encoding 則可以決定解碼方式,比如response.encoding='UTF-8’
response.json() 則能將reponse的內容轉成字典(json-like)物件
標頭相關
標頭(header)可以提供很多網頁的基本資訊,比如content-type ,date …..
response.headers 會回傳類字典物件,舉例如下

HTTP get method
常用參數
最基本的要求資料方式
get 除了可以給url之外,也能給其他參數使request應用更靈活 (和post最常被使用)
- params 可以加入QueryString
- headers 可以輸入headers資料
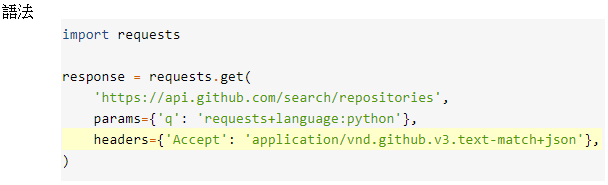
比如有時被403拒絕就是缺少user-agent
可加入my_headers = {‘User-Agent’: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36’} - 認證 Authentication
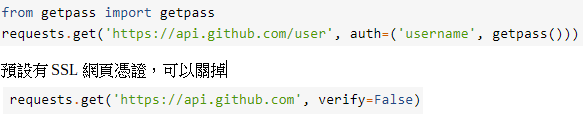
有些網站會要求認證,否則給予401拒絕
用法
- TimeOut
於每個HTTPmethod中都可以添加此參數,防止花過多時間等待連線
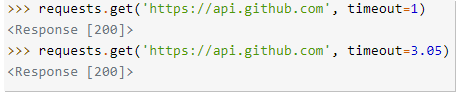
如果超過timeout則會反為Timeout error
(預設會等待連線無限久) (單位:秒)
也可以傳tuple 如 timout=(2,5) 前者為連線時限,後者則為讀取時限
其他method
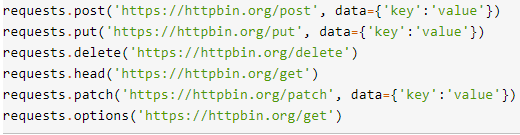
- 常用的post方法是用來透過message body傳送資料,因此後面會附上data參數 如果需要json格式也可以使用json參數傳資料
session
session可以維持參數的傳遞,比如收到的cookie、連線的message body
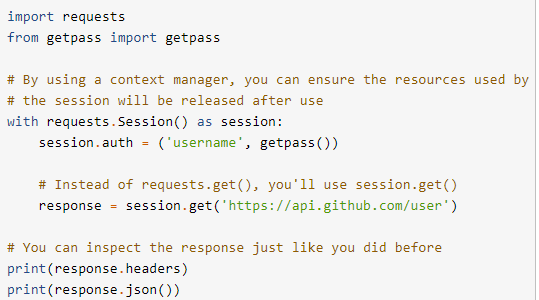
- 補充:Cookie
目的:因為HTTP是無狀態的,所以為了識別用戶,cookie應運而生 (eg 購物網站)
型態:通常為一加密的小型文字檔案,某些網站為了識別用戶而存在用戶端的資料
特性:1.Cookie會被附加在每個HTTP請求中
2.包含用戶名、電腦名、瀏覽器…等資訊
3.不同瀏覽器即使在同一台電腦也會有不同cookie(瀏覽器–網站)
應用範例
爬取ptt八卦版需要年齡驗證
解法: 使用post + data的參數 + F12去找Post的data+使用session物件實例來傳遞(共享)資料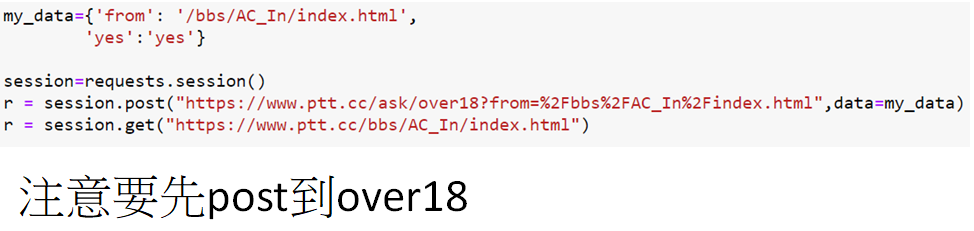
被403 forbidden
解法: 模擬user-agent
head = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'}
Response= requests.get(url,headers=head)
- Note: 如果被鎖ip 可能要使用proxy來解決
其他棘手情況
可能要採用selenium模擬網路瀏覽器的方式破解
參考資料
requests 官方文件
https://realpython.com/python-requests/#getting-started-with-requests