目錄
URI VS URL
網址的正規化表示
Query String Fragement
URL的設計原則
http傳輸內容
概述
-
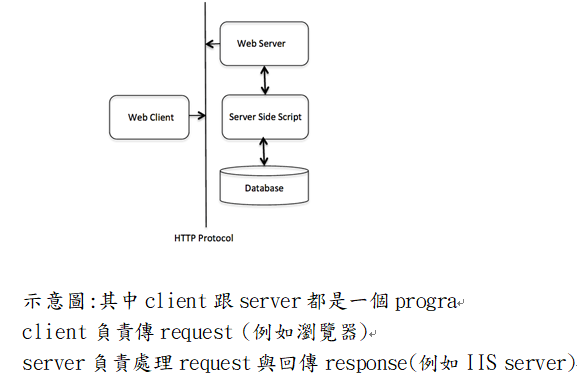
HTTP是建立在TCP/IP之上使用request/response的client/server協定,屬於第五層apply layer的協定
-
HTTP有三大特性:
1.Connectless:
client、server此次傳封包時認識到對方,即使下一次傳同樣的組合也不會有任何記憶 ==>不會記連結==>省下傳輸時間
2.media independent:
只要是雙方(Client/server)看的懂的資料(符合MIME),都可以傳==>用甚麼媒體傳都可以==>可傳多型資料
3.stateless:
不會記錄任何狀態嚴格來說1也包含在內)==>網頁間與封包間無法得到彼此資訊==>資安佳+較有效率
補充.MIME
多用途網際網路郵件擴展MIME,Multipurpose Internet Mail Extensions
是一個網際網路標準媒體型態,是網路郵件的擴展標準( 時代的痕跡,email至今的附件也是符合MIME的標準喔!),而HTTP得知傳送資料的媒體型態則是通過傳送內容中header的content type 常見型別有 HTML、普通文字、jpeg、mpeg圖片、au、midi聲音、gzip、tar壓縮檔、avi 影像檔 … 可以說因為MIME的加入使網頁的傳輸內容更加豐富
URL
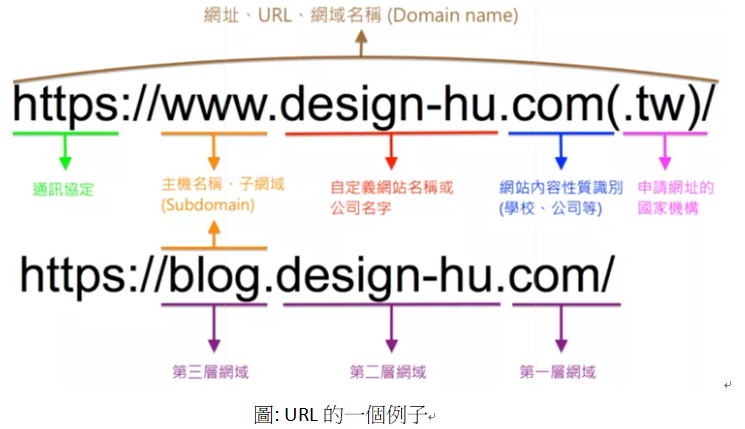
URI VS URL
URI (統一資源識別符)類似於DB中 primary key的概念,任何能唯一定位資源的規則都可以叫URI
比如 身分證字號可以唯一定位國民
URL (統一資源定位器 aka 網址) 是 URI的一種特例,指以 協定/網域/地區 ..的方式定位網頁資源的一種規則
網址的正規化表示

補充: port
此指軟體邏輯上的port (IP像旅館地址、port則像房號)
為TCP/UDP協定中傳輸層中對應的端點
port由16位元無號整數編號 (0~65535)
其中0-1023 是習慣上使用的port (well-kn own port)
如
HTTP 使用80
HTTPS 使用443
FTP 使用20、21
0 被保留不使用
補充2 網路五層架構

Query String
以?開頭,以key=value格式附加在URL後面,以指定資源的方法
如有多個鍵值,則以&分開
比如 ?age=24&gender=female
Query String存在保留字元,以byte為單位,並且% 加上 兩個UTF-8 編碼下的16進位數進行表示
比如
: 為 %3A
空白為%20 => 也可以使用 +
中文佔3byte,比如漢字[勝] 表示為 [%E5%8B%9D] => 也就是為甚麼URL可以有中文
補充:由於會將明文寫在URL上,不能放上敏感資料
同時也有可能被SQL insert 攻擊 ,有資安上的疑慮
fragement
是由client端(常為瀏覽器)處理的部分,不會傳遞給server
通常使用在AJAX或 單頁應用程式SPA,控制fragment做出效果
最初目的類似於超連結
補充 SPA (single-page application)
是一種網路應用程式或網頁的模型
類似於AJAX的目的,透過動態重寫當前頁面達到與使用者互動的效果
URL的設計原則
最好能做到以下幾點
1. 盡可能少更改
在提升server性能、更新資源的同時,盡量不需要更動URL
2. 通用性、抽象化
資源可以有多種表示方法,應以header或其他方式溝通好,而不應寫在URL中
https://example.com/myfile (O) https://example.com/myfile.json (X)
- 補充: Hugo的網頁雖然以markdown寫成,但連結URL時一樣不會加上.md
3. 要求、目標的獨立
我們不應混淆要求行為與目標資源,然而這卻常常被混用
比如
https://example.com/createUser?id=2020
https://example.com/user?action=Create&id=2020
將創造使用者 與 查詢資源混用
正確的URL應該只有查詢資源的功能,比如我要求使用者2020的資料:
4. 其他
*相同的資源可以有多個URL以減輕server負擔
*URL的階層性架構 (/)可增加可讀性與可預期性
(比如 網路概論講義依章節放在Web101/ 底下)
傳輸內容
傳輸內容分為四個部分為四個部分
Start line 、 header 、CRLF、 資料本身
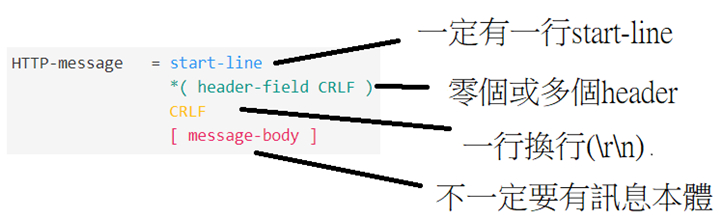
1.Start line
####Request 依序包含 請求method、空白、request-target、空白、HTTP版本、CRLF 比如: POST /task?id=1 HTTP/1.1
補充1
方法 作用 GET 請求指定頁面資訊 HEAD 類似於get,不過只要求header POST 向指定資訊提交資料 (比如八卦版的over-18、登入的帳號密碼..) PUT 上傳資料,取代指定內容(post不一定會修改內容,這也是put與post最大差異) DELETE 請求刪除指定資訊 CONNECT HTTP/1.1中更改連接方式的請求 OPTIONS 供客戶端查看伺服端的訊息的請求 TRACE 查看伺服端收到的請求,用於debug
補充2: 請求目標有四種格式,(後續待補https://notfalse.net/49/http-message-routing)
不一定是URI(統一資源識別符),原因是舊時代ip == 網域的技術債
補充3:網域名稱 與 ip
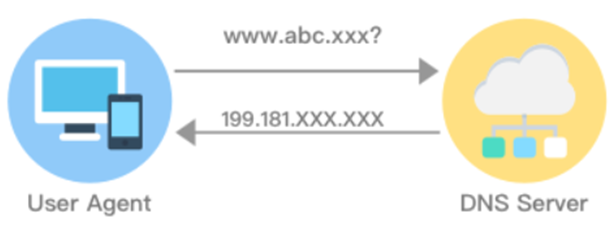
因為ip數字對人類來說難以記憶,我們會將ip轉為網域名稱 (如 111.111.111 => apple.com) 而這些名稱與ip對應的Table,會被記錄於DNS中,每次輸入網域名稱都要去查找
補充4. CRLF(carriage return followed by line feed) 白話文就是空行
實際上是 \r\n 也就是 carriage return (回車) 加一行 newline
為早期換行標準,並被持續沿用至今
Response
寫上 協定版本 與 HTTP 狀態碼 (又稱status line)
依序由
HTTP 版本 空格 狀態碼 空格 原因短語 CRLF 組成
比如HTTP/1.1 200 OK
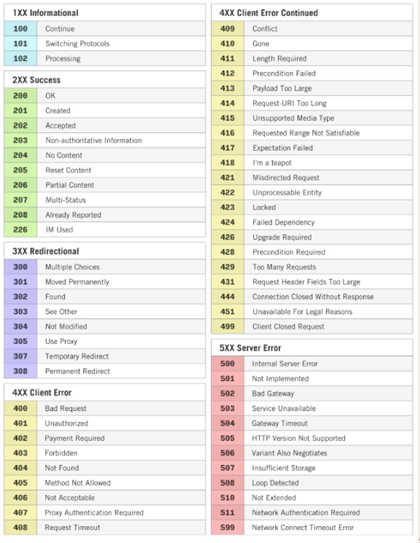
補充1: 狀態碼與短語
其中 常見的404 403 屬於錯誤的4XX 類
200 屬於成功的2XX 類
2.header
由0個或多個header-field 所組成
就是類似於json 的 key-value配對
目的在描述目標資源的附加重要資訊
比如 日期、檔案格式、檔案大小 …

- 由於 header-field 可以是任意資訊,所以有分為標準與非標準
其中標準由 網際網路號碼分配局(IANA)所制定
(https://www.iana.org/assignments/message-headers/message-headers.xhtml)
甚至在這份筆記製作的年中(2020),仍有更新
3.CRLF
表達 header的結束
4.message body
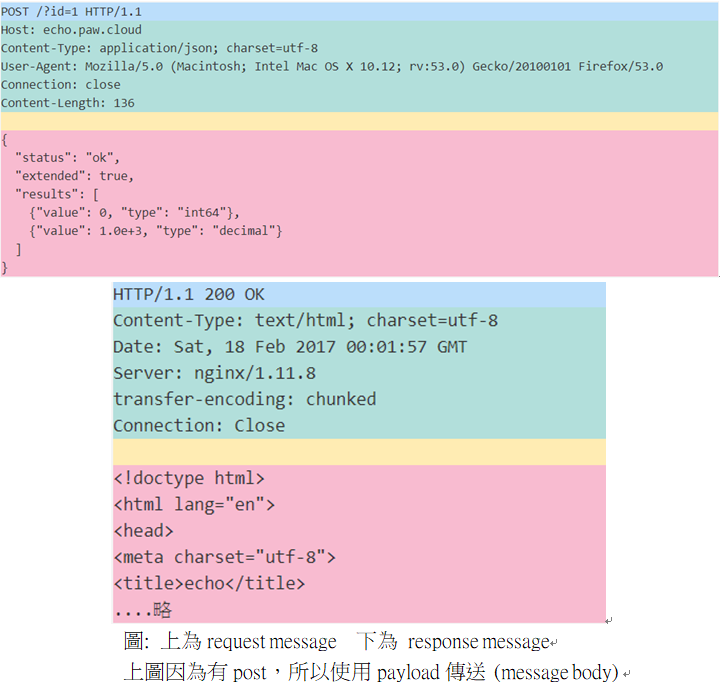
傳送的目標本體,可以以各式資料型態(只要符合MIME),並且以payload 格式傳送
request方除非post需要傳payload,有可能省略message body

補充 payload payload不考慮資料型態,只考慮位元組本身 並且是傳輸時預期的資料
參考資料:
大神寫的文圖並茂的教學
https://notfalse.net/http-series