簡介
此篇講解OS的process基礎概念
process 定義
process VS program
process 是動態,被載入記憶體中執行的程式
program 是靜態,被儲存於硬碟的binary code
process大致由以下幾區組成
Code segment(text section)
Data section: globa var
Stack: temp、local var
Heap: dynamic allocated var
Meta data : program counter , register contents
A set of resource : 如被開啟的file
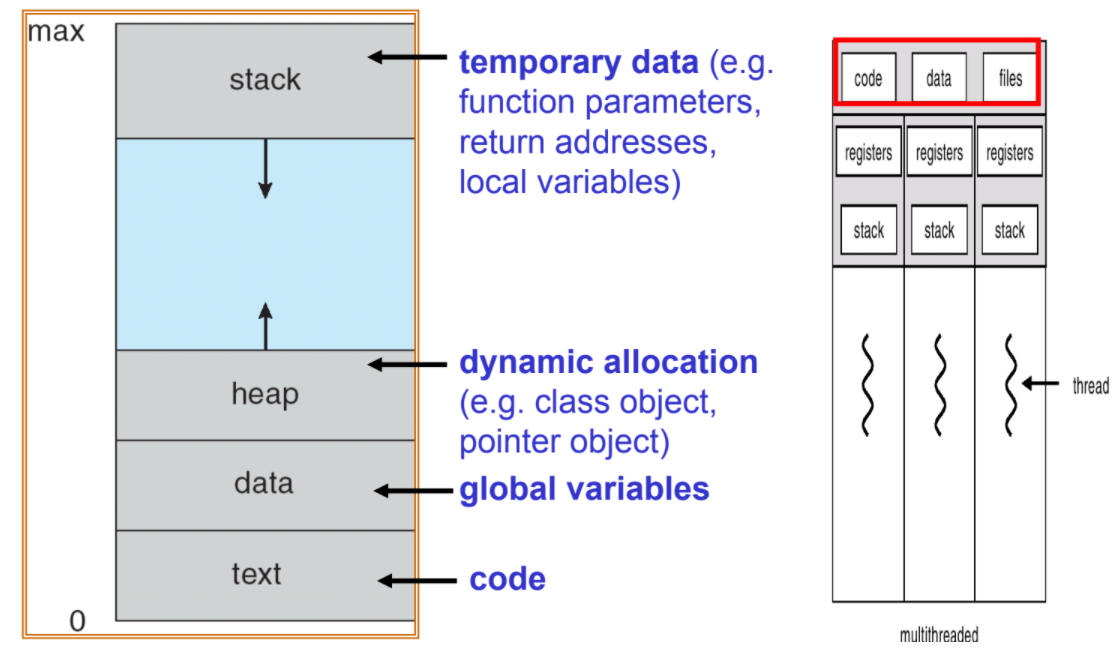
- 補充: thread是一種輕量版的process,也是CPU執行的最小單位,會share process的code,global data,file (注意:register不share,可以以PC記憶)
process state
process的排程可以以狀態轉移圖表示
共有以下幾種狀態
New: process被創造
Ready: process被載入memory,等待被執行
Running: process在CPU內執行
Waiting: process等待事件
Terminated: process執行完畢
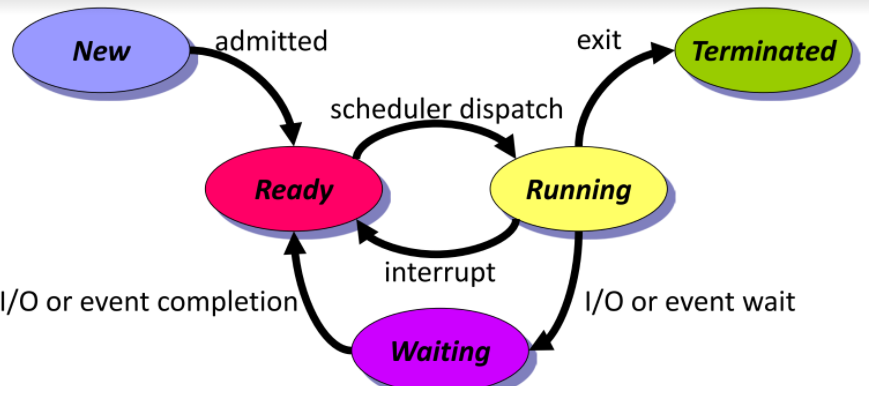
注意:
- ready狀態是否進入running,是由process scheduler(一套演算法)決定
- Running => Ready,非自願性,比如執行太久,time slice到了,或是別的程式IO完成
- Running => Waiting, 自願性,比如需要IO、或自知要等待事件
OS管理process的方法
使用PCB (process control block) 紀錄資訊
在process創建時,OS會創造的一個table物件進行管理
這些資訊會被放在kernel space memory裡面

為甚麼會有pointer?
“因為把process放入Queue中"這個概念,在實作上就是用Linked List把PCB串起來
重要資訊
process state , program counter , CPU register 這些OS需要的information
CPU scheduling information (如:priority)
Memory-management (如: base/limit register)
process 與 Context Switch
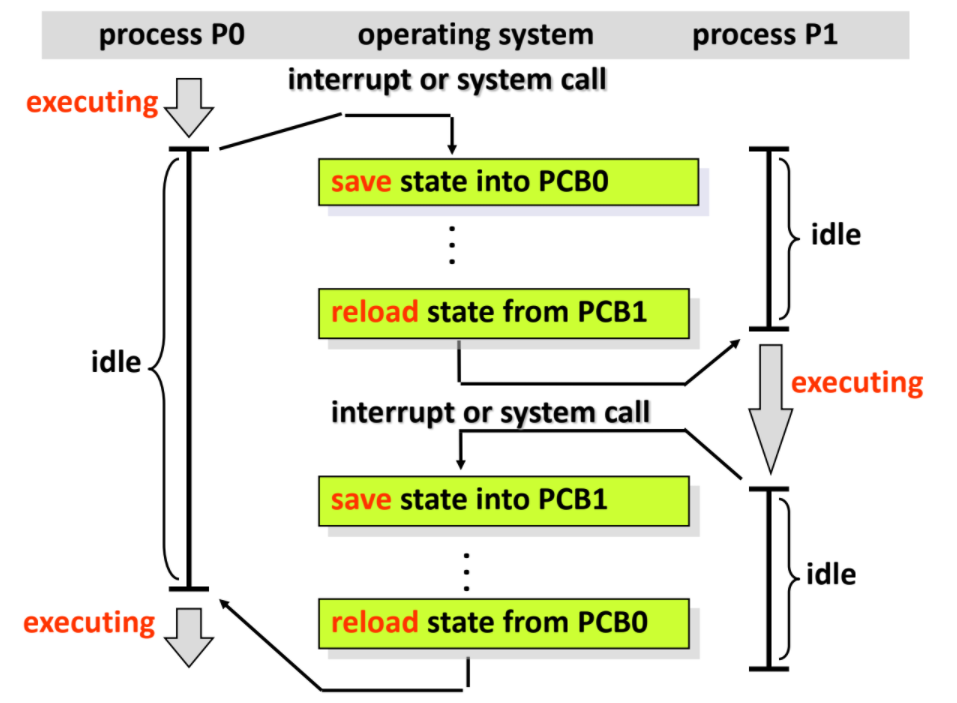
在OS切換process時,都必須save-reload process資訊,但這些時間(switch time)就是overhead
switch time時間取決於
memory speed
number of register
特殊instruction (如單行load/save)
hardware support (如多個set的register ,用於紀錄多個process狀態,減少memory access)
process scheduling 簡介
Review: 為甚麼需要process scheduling
為了要最大化使用CPU => 需要multiprogramming
為了讓使用者有即時互動感 => 需要time sharing
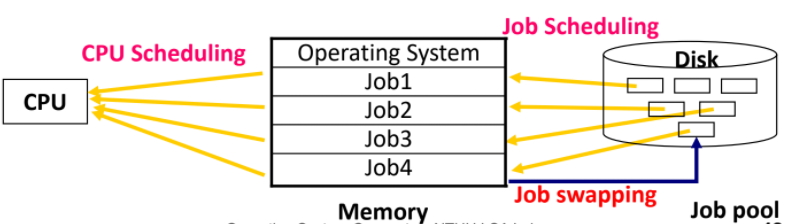
Queue
process scheduling 會使用多個Queue來管理process
- Job Queue : 存放new state,放所有process
- Ready Queue: 存放準備被執行的process
- Waiting Queue: 等待I/O的process , 一般會依device分為多個
下圖是個例子
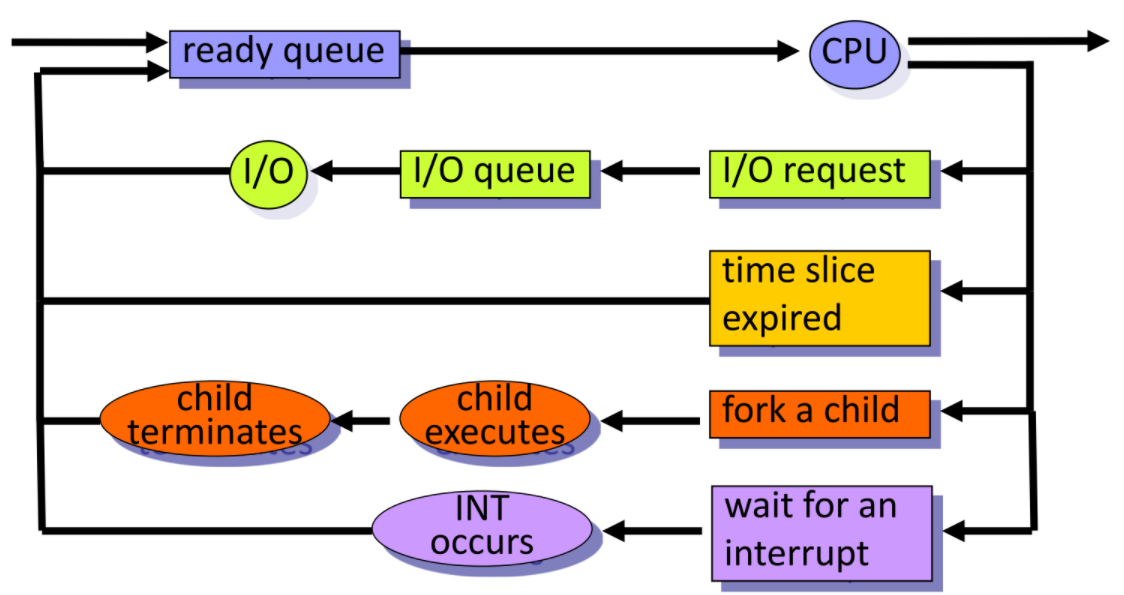
scheduler分類
short-term (CPU scheduler) : 決定誰該被CPU執行 (ready -> run) (幾ms就schedule一次)
medium term : 選定誰要swap out/in (ready -> Disk) (為了要清出memory,把程式放回Disk上等待IO)
- 現今Disk虛擬記憶體技術日漸改善,所以此角色重要度也有所下降
long term(job scheduler): 決定誰要被load 進memory (Disk -> ready)
(決定 degree of multiprogramming
如果容許選的太多,會造成競爭,如果限制選的太少,效率會變差)
- 在現今memory夠大,基本上不需要long term scheduler,此角色被medium term取代
process 實作
可以配合此篇一起閱讀
process tree
process會有parent , child關係,並且有自己專屬的資料(如:pid、register …),這正適合用tree表示
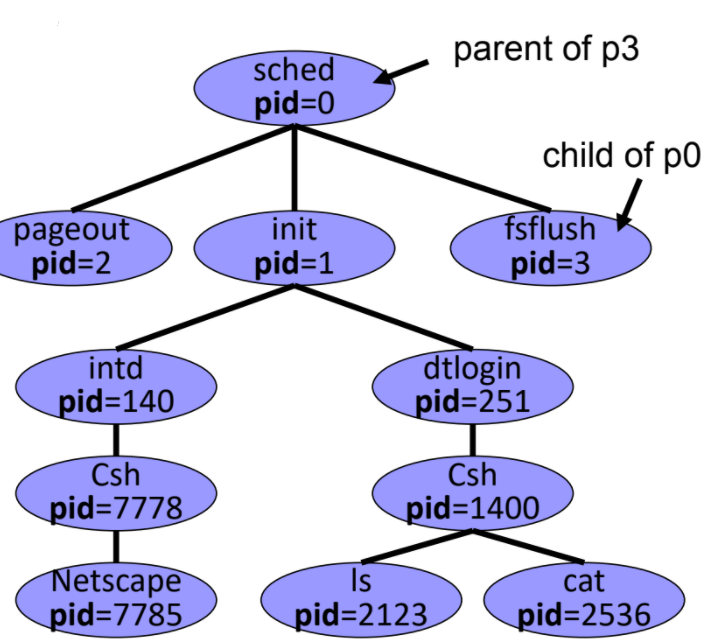
可使用unix指令: ps -ael 查看
process 設計
- 父子共享資源關係
可以是 全部共享、部分共享、全部不共享 - 執行順序
可以是同步執行 或 parent 等child - address空間
child 是parent的複製品,兩者用變數溝通
child 是直接load 新程式碼,兩者用message passing 溝通
Interprocess Communication (IPC)
定義:一套process間交換資料的方法 (網路也是廣義的IPC)
目的: 交換資訊(網路)、加速計算、方便管理、模組化(micro kernel)
方法
- shared memory
共同memory,兩者都可以取用
缺點:需要synchronization
優點:快速
作法:要跟OS要一塊memory
使用者自行決定怎麼利用這塊空間
並要管理synchronization問題
以consumer & producer problem為例
producer會寫入、consumer會讀取

注意:此法需要犧牲一格 (in+1)%B=out 表示in那一格一定是空的

OS 是很常使用這套方法的,比如compile (in) link (out)的pipeline
- message passing
類似email,直接傳訊息
缺點:需要copy、send、recieve,較慢
優點:跨電腦、小量資料的首選
本身就解決同步問題(打電話時,對方接起來,本身就已經同步了)
需要準備
- 溝通連結
- receive/send api
讓程式可以透過send(message) , receive(message)來溝通
溝通連結
又可分為physical (shared memory(傳送時才開,法I則是一直開著) , HW bus , network)
以及logical
定義方向、對稱關係、blocking or non-blocking (等不等待對方發/收到)…
-
Direct - 需要指定誰接誰收
send(P, message)
receive(Q,message)
(必定one-one 對應)

可以看到程式碼簡化很多
但會很死板,比如訊息無法重複利用 -
Indirect - 建立一個mail box共同收發
send(A, message)
receive(A,message) (many-to-many)
兩個人都到mail box A去收發
這樣訊息可以重複利用
-
Sockets:
網路以IP、port為節點,並以stream of bytes(沒有資料結構,要由協定決定如何解讀)交換資料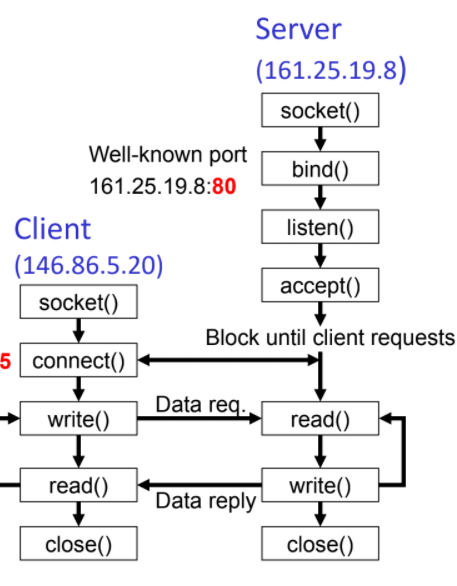
-
Remote Procedure Calls:
可以去call別人的API
與socket 差別,多了一層stub-skeleton去處理格式的問題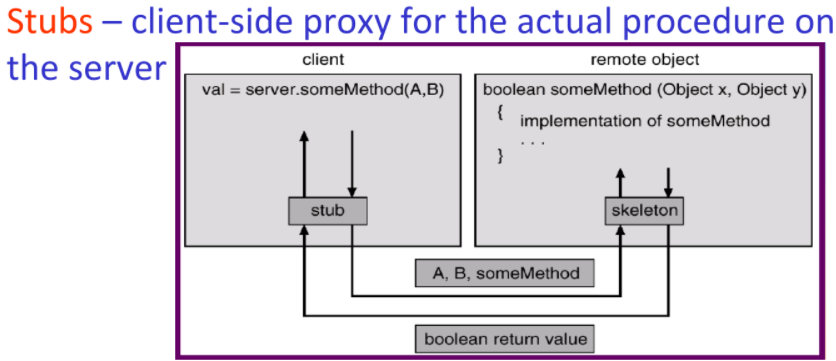
甚至底端還是socket傳,經過處理後變成方便的資料結構