記憶體是CPU直接存取的重要紀錄空間 也是process執行的地方
尤其在多程式情況,記憶體分配更為重要
address binding
variable , function, 整個process 如何對應到記憶體空間
有三個時機點決定記憶體位址
in compile time
in load time
in run time
並有兩種動態配置空間的方法
dynamic loading
dynamic linking
compile time
在Complie 時決定所有位址
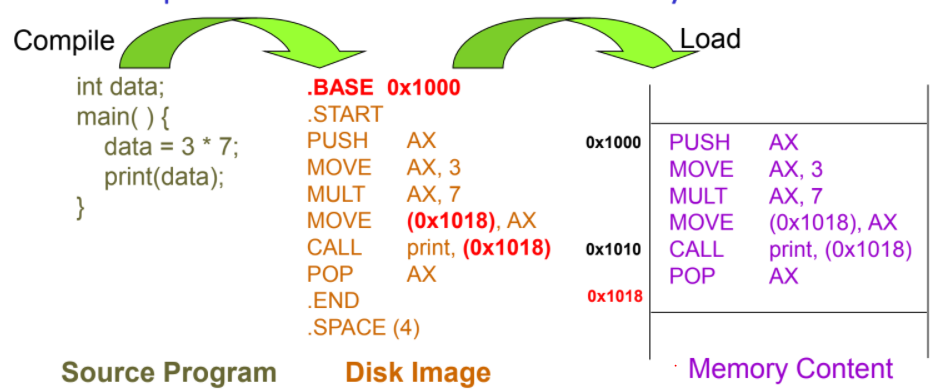
優點:簡單、快速
缺點:需要搬動時,要花大成本
為甚麼需要搬動?
- 虛擬記憶體要調配
- runtime時發現記憶體需要重分配
load time
會先用變數(暫存器)紀錄base address
等load time 時再由loader代入
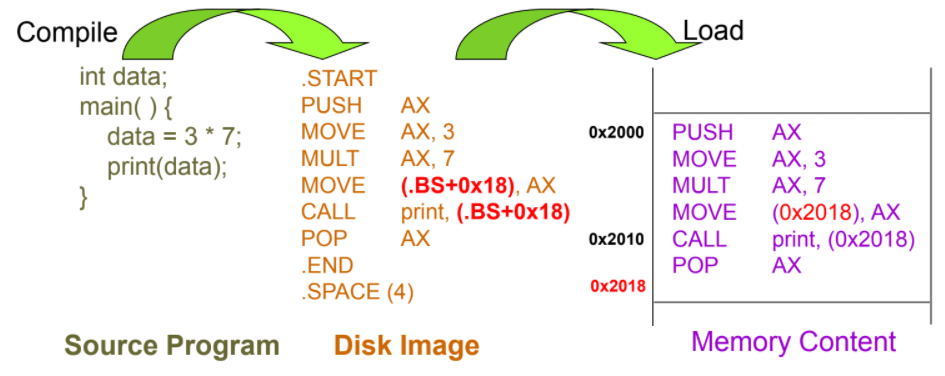
要搬動時只需要重load入memory就好
(不用重新翻譯C -> 組語 (aka complie))
run time
會區分邏輯上的記憶體 跟 實際上的記憶體
也就是使用virtual address,這樣就可以結合compile time的方法於virtual address上
使用MMU等特殊硬體去實現它
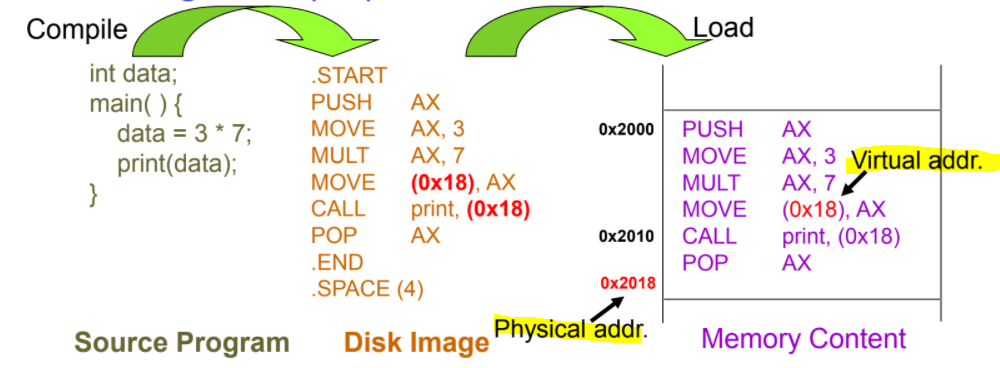
MMU - memory management unit
轉換邏輯與實際位址的硬體
CPU => logic address => MMU => physical address => memory
MMU 會放一個加法器,與紀錄轉換的register
logical + MMU register = physical address
dynamic loading
目標: 要用時才載入 程式執行時,需要用到的變數、函數才放進記憶體
比如工程師失誤(多要了多餘的記憶體)
error handling (要很大量,但常常只使用一點點)
如下圖, call到A才放進記憶體,並且執行完(比如C)會被釋放記憶體
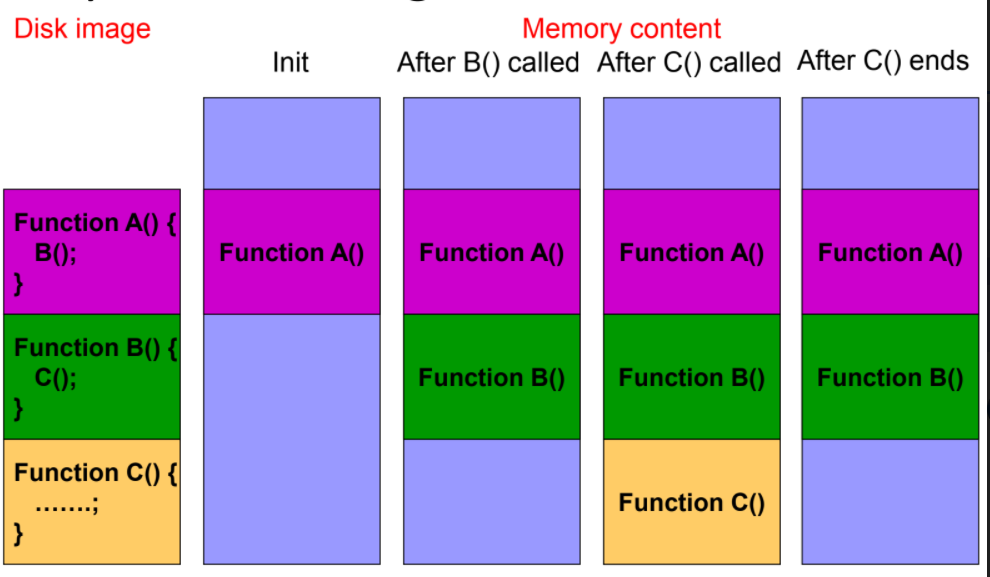
實作上,會使用C的 dlfcn.h 函式庫
並且對目標(如cosine function進行宣告)

目前實務上使用dynamic loading大部分已非節省記憶體
而是希望動態時決定function,以保有彈性
static loading : 全部候選人放進memory
dynamic linking
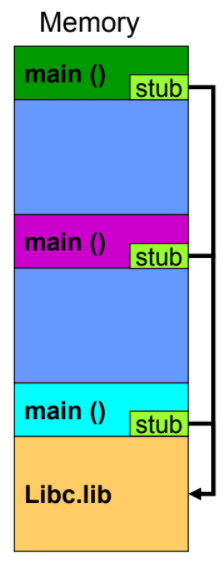
目標:重複的函式大家共用一份
如果A、B、C三個程式都需要my_function()
就算使用dynamic loading,因為都有需要,所以會重複三份在記憶體
但其實我們可以保留一份就好
-
DLL (dynamic link library) 也就是windows系列的動態lib,因為runtime才去找,所以常常是缺東西的主因
-
設定為dynamic linking,程式會自動加入一段小程式構成stub
static linking:重複也塞進記憶體
Swapping
process可能會被從memory swap 到 backage store
而backage store 是一塊disk空間
獨立於檔案系統外
swap 可以增加空間使用效率、讓重要的process放在memory裡
swap 一定要發生在目標process在idle時
(I/O也不行,因為資料會寫到記憶體裡)
實作:
- 在使用(含IO)就不允許swap
- 先把IO資料存在OS buffer
剩下virtual memory會討論更細
(比如swap成本、準度)
Memory Allocation
通常分為連續型與非連續型
差別在同一個process記憶體是不是在同一塊
連續型
Fixed-partition
每個process 都分配固定大小記憶體
問題: 小型程式會浪費空間
Variable-size partition
會找process 間的空隙放入新process (Hole)
但是常常新process大小不等於Hole
因此會有三種策略
- First fit : 塞第一個找到的hole
- Best fit : 塞進塞入後留空白空間最小的hole
- Worst fit : 塞最大的hole
通常採用1. 以減少scan disk 次數
並且Worst fit 有時也不一定最差,因為塞最大hole之後,還會留下很多空間,而best fit可能塞完後留下一堆細小、無法利用的hole
Fragmentation
也就是留下的hole
依partition兩種方法,也有兩種類型的fragementation
-
External fragmentation:
發生於 Variable-size partition
也就是process空間之間的hole -
Internal fragmentation:
發生於 Fixed-partition
也就是process分配到固定空間,裡面沒用完的hole
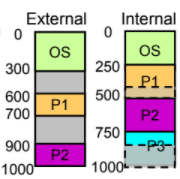
Internal fragmentation可以使用compression解決 (把process往同一個方向移動,直到緊緊密合,這也是清理硬碟的概念)
非連續型
概念上就是利用logical、physical 的對應
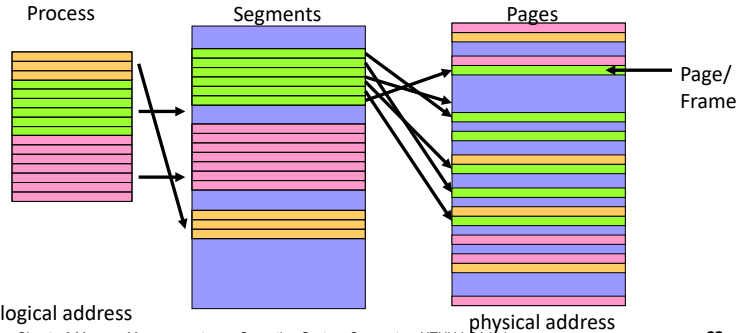
paging (fixed-size)
logical的分割叫做page (查頁碼)
physical的分割叫做frames
好處:對user而言記憶體是連續的(邏輯上) 提升空間使用的同時,降低programing 複雜度
如下圖,中間就是俗稱的page table
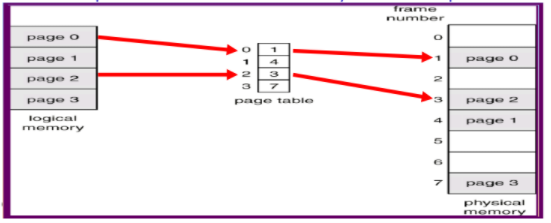
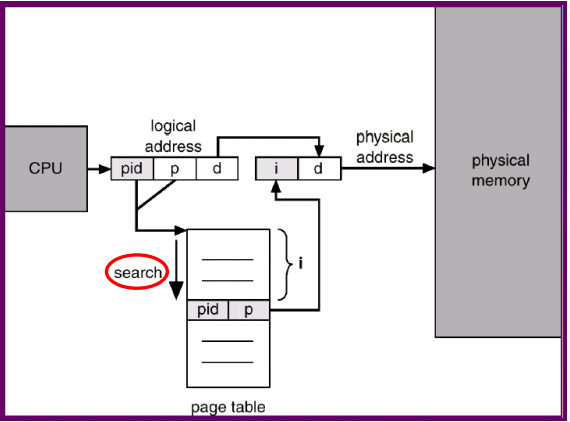
page table 概念
每個process都有一個page table (所以OS會要maintain大量page table)
frame size == page size
因為是預計要放相同程式
logical address有兩個部分
Page number 與 page offset
- Page number (p) 表示第幾個page
n 個 bits決定最多能使用 2^n個page - Page offset (d) 表示page裡面的位置,加上base address就是實際記憶體位址,並且也是實體記憶體的offset
n個 bits決定page size 為 2^n
(ex: 4096 bytes的page size,表示12bit去紀錄)
查表方法
- 由page number 查表得到frame number
- 把結果與page offset 串接
cat(pageTable[p] , d )
page size (frame size) 取捨
size太大: internal fragmentation會太多 => 空間浪費
size 太小: 現今process memory越來越大,size太小會造成process被分割到更多frame,因page fault等原因會使效能降低 並且frame多表示紀錄的overhead也多
Example1 address translation
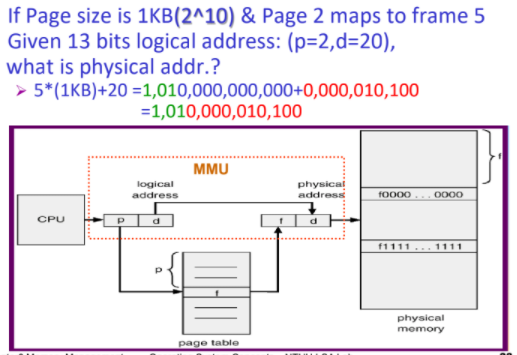
(註: 這題假設logical bits length == physical bits length)
先決定大小
-
首先了解1KB ==> page offset 有2^10 => 需要10bits紀錄
-
總共13bits => frame 用 13 -10 =3 bit 紀錄
再決定數值
-
page 2 根據page table ,得到frame 5 => 用3bits 紀錄,所以是101
-
offset 是20 => 用10bits記
=>0000010100
串接後得實際記憶體位址為 101 0000010100
注意: physical address 大小不一定需要等於 logical address大小
offset(page size == frame size 相等) 相等,但#frame 通常不等於 #page (#page < #frame 才能多工)
Example2
給定32bits 邏輯位址、36 bits 實體為址、 page size是4KB (2^12 B)
問
-
page table size?
page size 需用 12 bits 紀錄
故共有20bits長度用來記錄page編號
故有2^20 個page會被轉換
2^20個欄位 -
Max program memory?
一個process對應到一個page table ,一套邏輯位址
而此邏輯位址有32bits
故共有 2^32 bytes可供使用
2^32 byte=4GB -
number of frames ?
因為page size == frame size == 4KB
故frame 共有 2^(36 - 12) = 2^24 個 2^24 個
page table 實作
page table 被放在memory裡
page table 起點會被 page table base register 紀錄(PTBR)
PTBR 會記錄physical memory address
並且被process 的PCB紀錄
- 注意: page table 相當於要讀取兩字memory,一次透過PCB找到PTBR去載入page table (邏輯>實體),一次去讀取真的值
解決 2 memory read問題
使用translation look-aside buffer (TLB)
相當於cache概念,將以前讀過的先放在buffer裡,如果有中,就只需要讀一次memory
TLB 就是將一個process的 logical address 對應到physical address
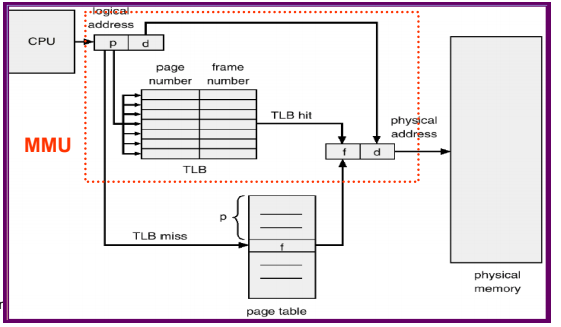
流程: 先查TLB,沒查到再去page table 找
如果context switch(換process)則TLB要清空(兩process同邏輯常常對應不同實體)
或是TLB要多記(pid,logical address)
Example: How fast is TLB?
20 ns 搜尋TLB
100 ns memory access
Effective memory access time (EMAT)
-
假設70% TLB hit
EMAT = 0.7*120 + 0.3*(220) = 150 -
假設98% TLB hit
EMAT = 0.98*120 + 0.02*220 = 122 -
沒有TLB
則要access兩次
EMAT = 200
page 雜記
Memory protection
通常會加入protection bit在page table 裡
紀錄logical address被對應的physical 當下能否被取用
PAGE table也是動態配置的,所以會有page table length register (PTLR) 去紀錄page table多大
- PTBR + PTLR 會決定page table 多大
shared pages
有時會需要共用page記憶體
條件是這些code是pure code - 不會在執行時間被改變
可用page table 多個logical address 對應到相同的physical address的多對一去實作
page table 問題
假如page table Entry數太大,並且一個page table entry需要一定程度的空間
(注意是page table 本身,不是page !!)
會造成page table overhead 太大
很難找到一塊連續記憶體放入
解法1 Hierachical paging
如下圖,把大table 拆成多層小table

實作上自然會把logical address多拆出一部分紀錄下一層表的index
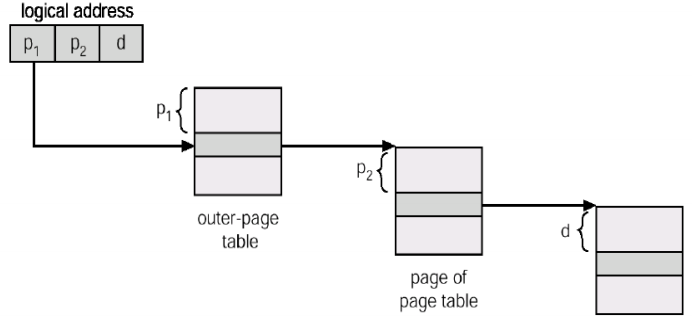
注意: 這個方法不但不會減少page table總大小,反而因為多記一層使總大小增加
但是可以使之分散
注意2: 會使access time 增加,n層table變access n+1次
實務上不採用
舉例而言,64bit大概就需要五層

但overhead會變超級大 (總量、memory access)
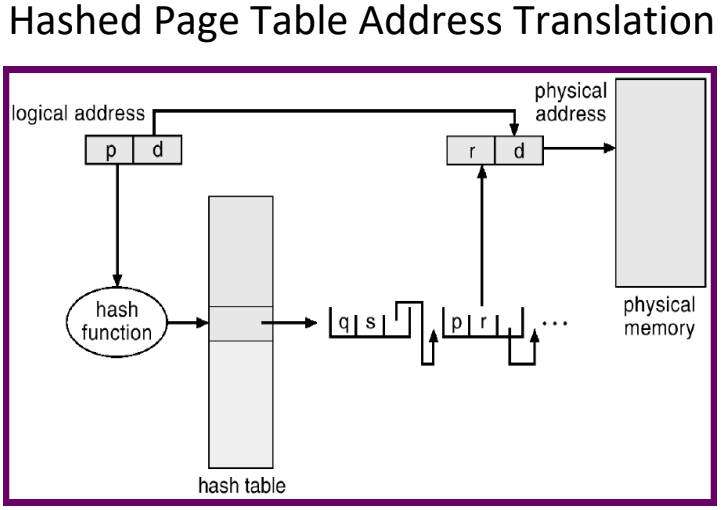
解法2 Hashed page table
hash table 如果產生碰撞就用linked list 串起來
相較Hierachical paging,能更有效利用空間(Hierachical paging 不一定全是滿的)
解法3 Inverted page table
不紀錄page table,改記錄frame table
為每一個frame紀錄 (PID , Page number )
這樣只需要一個固定大小的array即可
缺點:
- frame table很大,search成本大
- shared frame要額外設計
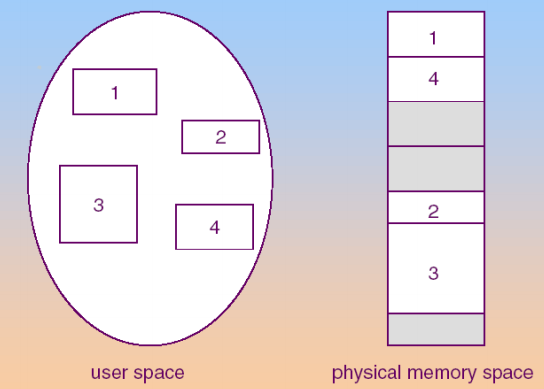
segmentation (varible-size)
以使用者角度去切割
類似OOP的概念,把程式切割成多元件
再以元件為單位去對應
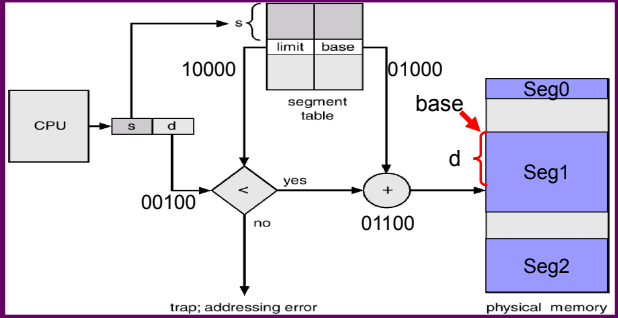
實作上,會用base address + offset的方式
並且也可以同時檢查是否是正確的segmentation
page + segment
可以先經過一層segment logical address
再用paging去對應到physical address