以一個決策問題開場
Q: 如何用最少的時間到達山景城?
- 腳踏車
- 開車
- uber
- 飛行
search problem:
以自動機的角度,目前就是輸入狀態s 與 行為a,轉移到新狀態Succ(s,a)
問題是現實問題中,一組(s,a)可能有隨機不同的結果
比如
機械手臂 決定移動軌跡,但可能有未預期的障礙
農業 決定種植甚麼作物,但可能有未預期的天氣
例子1:移動遊戲
影片中以一支的程式講解,其中各格會有獎勵與懲罰來講解
比如遇到岩漿 -50 ,到達目的 +20
並且可以調整隨機掉入岩漿的參數
例子2: 擲骰子
另一支的程式遊戲
每一回合可以選擇留下 或 離開
離開可以得到10塊,並結束遊戲
留下可以獲得4塊,並且投一次六面骰子
如果骰出1、2,則結束遊戲,反之進入下一回合
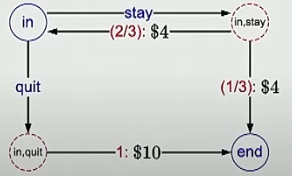
其中虛紅線被稱為chance node, 即轉移後的狀態是有機率性的
以此例而言,進入遊戲有可能輸,也有可能贏
並且就算結果存在100%也可以當chance node
這些例子中都可以使用期待值,來求出optimal policy
所謂policy,就是一連串的狀態轉移 (狀態,行為,新狀態)
Markvoc Decision Process 定義
Markvoc Decision Process 定義 (search problem加上未定機率轉移)
- T(s,a,s’) 移動發生的機率
從s採取a行為後,到達s’的機率
以上例而言

很明顯的 固定s,a 對s’求和必為1
- R(s,a,s’) 獎勵 (通常會追求這個最大化)
- 0 <= γ <= 1 discount (通常為1)
search problem 定義:
States : 一群狀態的集合
s_start 屬於 States : 初始狀態
Action(s): 所有可能在狀態s下採取的行動
Succ(s,a): 在s狀態採取a後會到的新狀態s’ => 對應轉移機率T(s,a,s’)
Cost(s,a): 在s狀態採取a後的成本 => 對應獎勵 R(s,a,s’)
IsEnd(s): 判定s是否為終點狀態
接下來影片使用一個問題與實際程式碼講解
問題:
有N段路
從N ~ N+1 要花一分鐘 (walk)
從N ~ 2N 要兩分鐘,並可能有0.5機率失敗 (tram)
程式會用一個物件包住上述的函式
What is solution
就搜尋問題而言,解就是狀態圖中從起始位置到終點位置的path , aka一連串狀態轉移
對MDP而言,解是policy,policy是一個將狀態映射到行動的函式
Policy evaluation
用衡量來決定policy的好壞
定義: utility
policy會創造一個隨機路徑
utility會將這條路徑上的reward加總 (取discount)
utility會是隨機的
以骰子例子而言

path會應用上折抵率
u = r1 + γ*r2 + γ^2 * r3 + …
γ
是表達對"未來"的調整
比如γ=1
就是save for future的感覺
γ=0
就是live in the moment (未來狀態不重要,也有種greedy的感覺)
γ 會依問題決定,通常不是超參數
定義: value
utility的期待值
E[u]
定義: Q-value of policy
chance node的utility
可以Recursive的定義

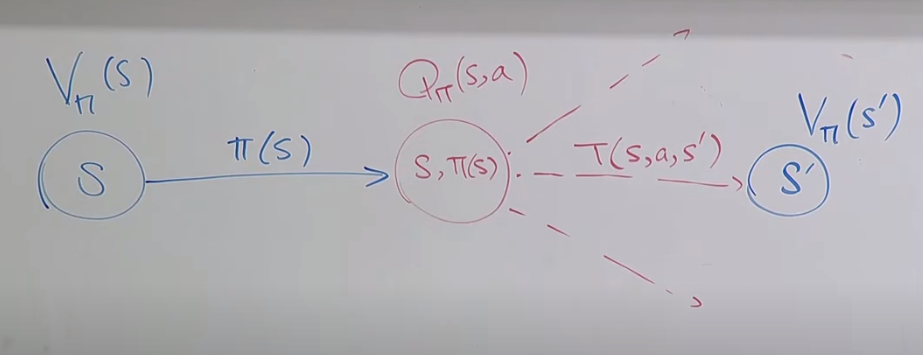
文字來說就是
[某點期待值]為
對於所有可能採取行為與他們的結果, 將(行為,結果)的發生機率乘上 [總獎勵] (獎勵期待值)
[總獎勵] 為 行為=>結果 的獎勵 與 [未來會發生的獎勵] (當下獎勵+未來獎勵)
[未來會發生的獎勵]則是 [該可能結果的點期待值] <= 此處為遞迴定義 (未來獎勵相當於用這套方法套用至未來點)
Dice Game 的例子
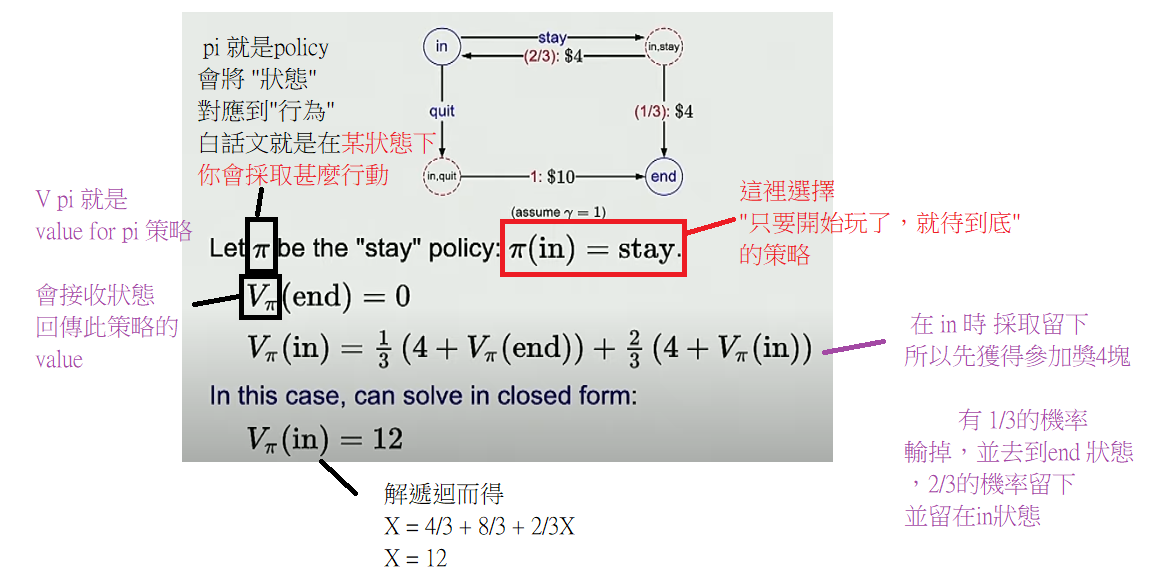
求 policy value值得演算法 : iterative algorithm
概念: 一開始隨機給值 (通常給0),然後重複求值,直到收斂
演算法
# init
for all states:
V_pi_0(s) = 0 # 對pi策略,0表示iteration 0
# iter
for iter = 1 ~ t_pe :
for each state s :
V_pi_t (s) = sum (T(s,a,s') [R(s,a,s') + gamma * V_pi_(t-1)(s') ] )
# 本回合的s ,由"上一回合" "周圍點" 決定
一個求值的例子

如圖,可以看出收斂至4
問題 : 何時該停止 (確定收斂)?
答案: 可以效法求小數精度 ==> 設誤差值
當 上一回合 與 本回合 的絕對值差小於這個誤差就可以停止
增進效率 : 只需紀錄上回合
由於本回合資訊取決於上一回合,上上之前的資訊其實都沒必要紀錄
(表格只需要紀錄前一行)
時間複雜度
O (遞迴次數 * #狀態數 * #每個狀態可能的結果狀態) (想想演算法)
可以試著用這套演算法解Dice game的解
大概需要跑100次迴圈
目前小結
MDP (markov decision process) 與
狀態圖形、chance node , 轉移機率、獎勵 有關
Policy(策略) : 一個將狀態對應到行動的函數 , 也是MDP的解
Value of policy : 於隨機path的utility的期待值
Policy evaluation : 一個迭代演算法去解value of policy
最優的值與策略
Goal : 找到期待值最大的策略 定義 optimal value : 在所有任意策略中,V_opt(s) 是最大的
很直覺的,要找到最佳值,就是要找到最佳策略opt
pi_opt(s) = argmax Q_opt (s,a)
一樣可以由iteration value 求法

只是這次需要每次都尋找最大值
時間複雜度
O (遞迴次數 * #狀態數 * 狀態可採取的行為 * #每個狀態可能的結果狀態) (想想演算法)
心得: 就是暴力的去嘗試所有的可能性而已
接著用程式實作 前面提到的走路題
Convergence
如果 gamma < 1 或者 MDP 沒有cycle => 一定會有收斂值
(有環又gamma == 1 => 沒有收練值 )
Relaxation
概念: 解除一些限制,得到近似解、或更簡單的問題
再用以有的(經驗的 heuristics)方法去解決
比如 把障礙物去掉就可以用曼哈頓距離解決
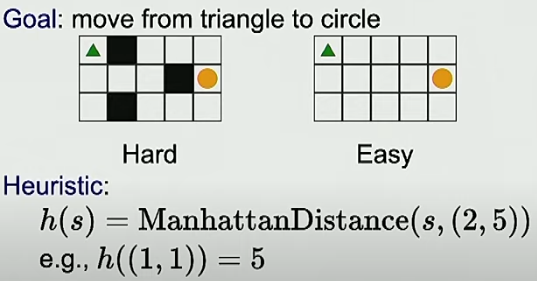
以及走路題 去掉條件,可以使用DP解

 讓經驗解 h(s) 趨近 FutureCost(s)
讓經驗解 h(s) 趨近 FutureCost(s)
如果差太多則不能使用
課程結束
補充:
MDP就是強化式學習(Reinforcement Learning )的基本概念
包括 上下狀態獎勵遞迴式、未來遞減率
Q-learning 剛好跟Q_policy很像
不過會有 其他參數
比如 greedy => 幾趴按照Q最佳解選擇,幾趴隨機選
比如 alpha => 此次結果多少比例用於更新學習 (也就是learning - rate )
參考
Lecture 7: Markov Decision Processes - Value Iteration | Stanford CS221: AI (Autumn 2019)
https://www.youtube.com/watch?v=9g32v7bK3Co&t=181s&ab_channel=stanfordonline