檢查training set 與 Overfitting
Deep Nerual Network常常被認為更容易overfitting
但事實上decision tree , KNN 更容易在training set上達到100%準確率
而Overfitting並不是單純參數多、表現差的代稱
應該是 testing set 比 training set 表現差時 才能推論
比如單純知道實際問題上 30層的網路 表現的 比10層網路差,並不能推論30層網路一定overfitting,必須檢查training set表現
有可能發生30層在training表現比較差
但理論上30層效能一定大於等於10層(最差就學會10層的參數,最後20層放identical mapping)
tips: DNN 在訓練完畢後,檢查training set是很重要的一步
Underfiting? 多層表現差?
通常underfitting表示 參數不足以擬合出好的模型 造成表現差,
而多層網路表現差,則不太符合這個定義
老師比喻: underfitting像是等級不夠
多層表現差像是小智一開始的噴火龍,等級夠但不想打
Vanishing Gradient 與 sigmoid
Vanishing gradient可能是造成多層網路表現反而較差的原因之一
其發生結果是在多層網路傳播之下,最後gradient變動越來越小,導致只有前面幾層更新很快 後面幾層很快就收斂卡在local optimial
其成因在sigmoid function
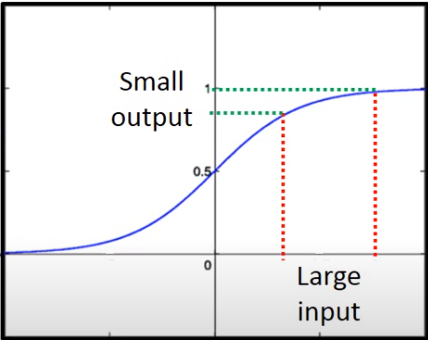
如圖,sigmoid會把實數域投影在0-1
會造成input大的變化,在output變動縮小很多
經過多層sigmoid,其變動當然會縮小到近乎消失
Relu
為了解決vanishing gradient
除了有人提出layer-wise的訓練方法外
也有人從根本提出新的activation function去解決
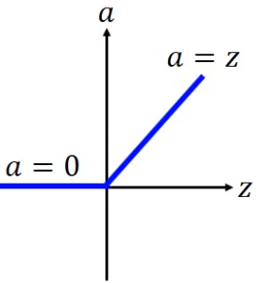
如上圖,此方法有參考細胞閾值的概念
在超過某個值後,有gradient
沒超過就是0
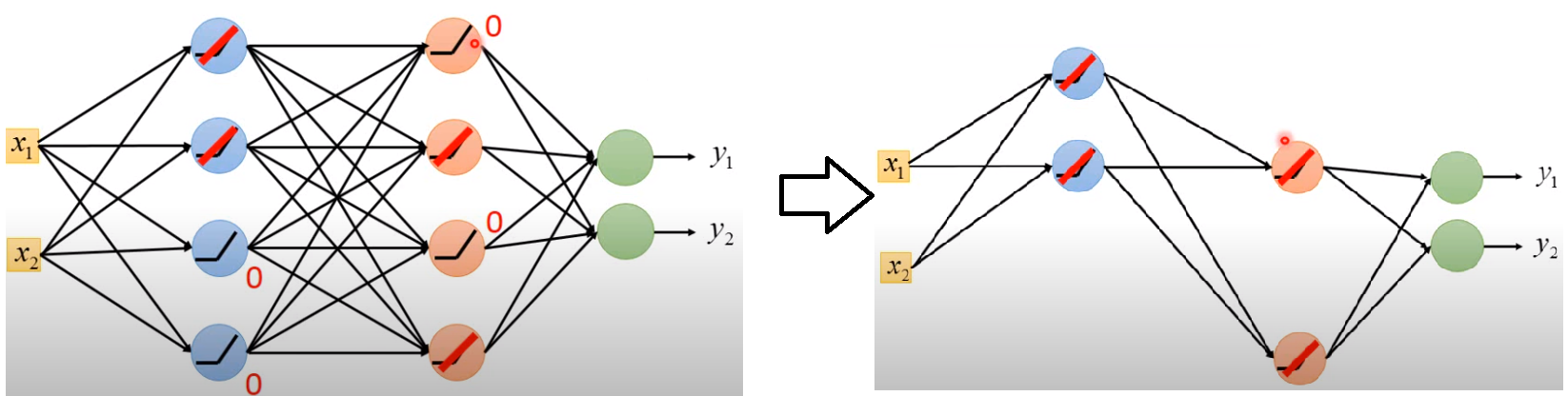
這樣相當於每次選擇某些cell做linear的計算
但對整個NN而言是非linear的
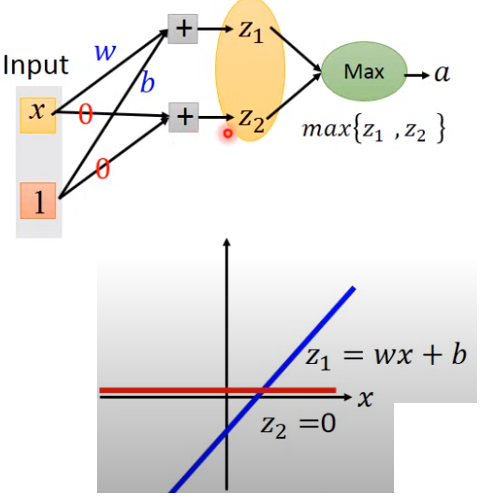
Maxout
連activation function都交給NN去學習
Relu以及其變體只是maxout的特例
如下圖,這方法也是類似CNN中maxpooling的概念,把output分成一個個group,並選出最大的作為最後輸出
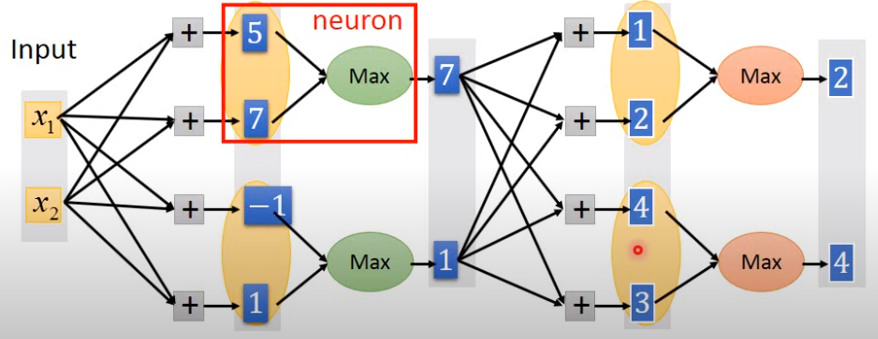
當然實作上,可以不只兩個輸出作為一個group 那折點也可以變更多
relu是maxout的特例
如何微分
對有通過的參數,就是線性function,那就可以直接更新,而沒有通過的可以先不用更新 大量資料總會train到它們的