前言
python的pandas是專門為矩陣型的表格式資料設計的套件 可以由pip install 安裝
此文希望紀錄我實作時比較常用到的功能
因為pandas的每一行數值都是Serial物件,而serial物件是以numpy實作的,因此套用numpy,sklearn等常用機器學習套件十分方便,並且sklearn格式基本上就是fit(DataFrame,Serial)
會使用到的套件
pandas
seaborn
此外也可以參考pandas_profiling套件來完成很多自動化工作
一.讀寫檔案與基本操作
讀取檔案
pandas可讀取常見的檔案,並自動轉換為pandas內的DataFrame物件
例如提供 read_csv(<file_name>),read_json(<file_name>),read_html(<file_name>),等函式
以下使用kaggle的經典房價預測問題的資料集進行測試
import pandas as pd
df = pd.read_csv("train.csv") #下載並放在同個資料夾的測試集
df就會得到整個表格的DataFrame
當前處理完畢,如果想要重新輸出一份檔案
也有 df.to_csv(<file_name>),df.to_json(<file_name>),df.to_html(<file_name>) 可供使用
初步了解Data
接著pandas也提供幾個函式初步查看表格資料
比如
df.info()會輸出各個coloumn的名稱、type、多少個非null值,以及有多少column等資料,方便綜覽整個表格在紀錄甚麼
df.describe()則會輸出數值型資料的個數、最大、最小、平均、標準差、四分位數 等基本統計數值,方便了解整個數值分佈
以上函式也是回傳DataFrame,因此想查看特定行也是能直接取用的,
以kaggle資料集為例,想看看土地面積的統計量,可以使用
df.describe()["LotArea"]
了解基本資訊後,也提供df.head() 與 df.tail() 取出前後幾列看看幾個例子,括號內可以放整數參數決定取幾列
df.skew() 可以看出資料的偏度
算法為 三階中心動差
若資料分布對稱,則skew 接近0
若大於0,則極端值偏向正數側
若小於0,則極端值偏向負數側
df.kurt() 可以看出資料的峰度
算法為 四階動動差 除以 標準差的四次方 - 3
若資料為常態分佈 則kurt趨近0
若大於0,則資料集中,稱為尖峰
若小於0,則資料分散,稱為平峰
取用Data的部分
1. 直觀方法
接下來可能需要分析特定幾筆數據、幾個特徵,因此需要了解怎麼選取行列
基本上可以把DataFrame看作是一個key對應到numpy array 的dictionary
比如:
{"姓名":["小明","小美"],"成績":["100","60"],"性別":["男","女"]}
因此想要看任一行的資料,只需要 df["標籤名"]
其中又要看第n列的資校,只需要df["標籤名"][n],當然也可以用list slice選取多列
比較特別的是
-
如果要看不指定行的第n列,需要使用list slice(如
df[n:n+1]),否則pandas會以為你要找標籤名==n的行而回報錯誤(key error) -
如果要選取多行,則可以傳一個標籤名的list,比如
df[ ["姓名","成績"] ]
以kaggle資料為例,若要查看第51到100筆的 MSZoning 與 LotFrontage 可以使用
df[["MSZoning","LotFrontage"]][50:100]
2. 使用內建屬性
pandas也內建屬性供選擇行列,即為loc與iloc
loc代表location,可以使用df.loc[起始列數:終止列數 , 起始標籤名:終止標籤名]
比如kaggle資料集例子
df.loc[5:10, "MSZoning":"LotShape"]
就能取出第2行(“MSZoning”)到第8行(“LotShape”),的第5列到第10列資料,共36個欄
位
而iloc代表interger location, 也就是將loc行標籤名換成行號的版本,使用格式為
df.loc[起始列數:終止列數 , 起始行數:終止行數]
所以以下列子與loc得到的結果會是一模一樣的
df.loc[5:10, 2:8]
- 特別提醒
- df的loc與iloc的使用方式很像list slice,但是有包含終止index
- loc , iloc 是property,而非method,因此不須加( )
二 依條件選取資料
這一小節會介紹pandas類似資料庫的select功能,是為了接下來的前處理做準備,因為前處理可能針對不同條件的資料做個別處理(比如: 數值與屬性資料、極端值資料、空值資料 …)
注意以下method大部分都會回傳DataFrame,因此和pyquery或字串處理一樣可以用chain的方式連用
依位置選取
已在上一節介紹過loc與iloc可供使用
依型態選取
pandas提供df.select_dtypes(),並有exclude, include參數方便選取或反向選取,以分開不同類型的資料
而Pandas的資料型態是參照numpy的,資料型態參考這裡
要 選取 特定類型資料,可以用df.select_dtypes(include=[<your_type_list>])
比如:
df.select_dtypes(include=["int64","float64"])
會選取表格內是int或float的資料
要 去除 特定類型資料,可以用df.select_dtypes(exclude=[<your_type_list>])
比如:
df.select_dtypes(exclude=["int64","float64"])
就不會選取表格內是int或float的資料
依判斷式選取
df[判斷邏輯式]即可輕鬆選取符合判斷式的資料,這是非常實用的技巧
判斷邏輯式 由以下規則組成
判斷式 := (判斷式) [&,|] (判斷式)
判斷式 := [df.標籤名] [判斷符] [值]
重要1: 多個判斷式要用括號包住
重要2: 判斷式之間要用&,| 而非and , or !
比如
boy = df.age < 18 & df.sex = "male"
pass = df.grade == "A" | df.grade == "B" | df.grade == "C"
- Note
- 此技巧也被稱為mask
- df的query函式可以得到相同的結果
- 上述例子也可以看到這些邏輯判斷式是可以紀錄成變數的
使用時可以這樣使用df[boy]
以範例資料集為例,我們可以使用df[(df.LotArea>8000) | (df.Street == "Pave")]來取得土地面積大於8000平方英吋、街道有鋪路的資料
丟棄資料
pandas提供df.drop()來指定丟棄指定欄位,回傳drop指定欄位後的dataframe
參數可以依row number list、標籤list指定,並由axis參數決定行或列(但不能使用list slice)
axis=0 表示由上而下的操作,所以會刪除橫向的列
axis=1表示由左而右的操作,所以會刪除直向的行
舉例說明
現在有一個dataframe如下
A B C D
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
df.drop(['B', 'C'], axis=1) 會刪掉 B C 兩行,留下
A D
0 0 3
1 4 7
2 8 11
df.drop([1,2],axis=0) 會刪掉第1筆與第2筆的資料,留下
A B C D
0 0 1 2 3
其他技巧 與 整合應用
以下會記錄一些比較細部的概念或技巧
1. 統計數值
統計數值幾乎都有被pandas實作
比如平均數、標準差、眾樹、中位數、極值
這裡提供一個例子,拿到所有數值資料的中位數,並取出LotArea的中位數,這個例子也同時示範chaining的技巧
Example:
df.select_dtypes(include=["int64","float64"]).median()["LotArea"]
2. 排序資料
pandas提供 df.sort_values 讓我們針對列值進行排序
Example:
df.sort_values("LotArea") #針對土地大小排序,由小到大
3. any與isnull -- 挑出空值
以下會告知該行是否有null值,也可以做為mask的判斷式
isnull()會讓整個表格轉換成True or False , 而真假與否取決於使否有null值
any()則會針對一列或一行做or運算 (當然也有all()可使用)
df.isnull().any(axis=1)
4. isin -- 挑出有特定值的資料
理論上也可以用 df.index == "a1" | df.index == "a2" | ... df.index == "an"
來辦到,但此方法明顯省時省力
df.index.isin([<value_list>])會將某行(標籤名指定那行)所有值有存在value list裡的列為True(看例子就很好理解),搭配mask就能取出那些列的資料
shape = ["Reg","IR1"]
df[df.LotShape.isin(shape)] #選取土地形狀是 Reg 或是 IR1 的資料
三. pandas繪圖
這一小節介紹如何用圖表呈現資料,這除了能幫助我們分析資料,更好的完成前處理步驟 (如:極端值、imbalance …),也能讓數據更直觀的呈現
pandas基本上內建以matplotlib為底層的基本繪圖功能,也可以與Plotly, Seaborn, Chartify 等較為高階的python資料視覺化工具搭配
參考:其他人對這四種繪圖工具的簡介
好用的Seaborn
這裡以Seaborn為範例
首先用 pip install Seaborn 安裝,然後用pip install -U seaborn更新
以下是一個例子
import seaborn as sns
num_data = df.select_dtypes("number") #選取數值資料
for i in num_data:
sns.relplot(x=i, y="SalePrice", data=num_data)
可以看到能簡單使用relplot(關係圖)函式,畫出數值型特徵與預測目標SalePrice的關係圖
並且這個範例也告訴我們基本的參數使用
預設為散佈圖,將參數kind="line"加入可以變成折線圖
此外也有displot(分布圖)與catplot(質性資料圖)等好用工具
資料視覺化101
1.定義
資料視覺化的定義可以參考這位大神的文章
資料視覺化是將資料中的變數映射到視覺變數上,進而有效且有意義地呈現資料的樣貌 同時目的是分析資料 與 呈現資料
2. 各圖使用時機
基本上可以參考Seaborn官方基本教學提供的圖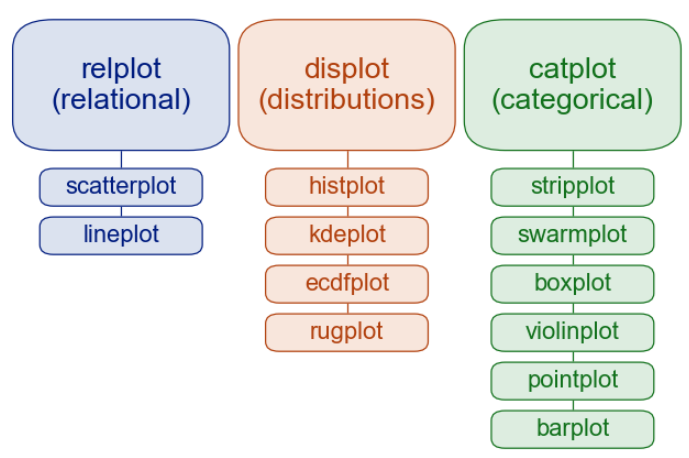
relplot 是數值與數值資料之間使用的,可以看出趨勢、相關性
displot 是數值 或 質性資料 使用的, 可以看出出現次數分布 (所以不用y參數)
catplot 是數值與質性資料之間使用的,可以看出質資料與數值之間關係
四. 前處理 與 資料清洗
在資料工程中,前處理與資料清洗有助於後續更好的應用,而Pandas自然也提供了許多此方面的功能
處理缺失資料
原始的數值資料中,常常可能會有缺失或空值(通常以NA(not applicable)或NAN(Not a number)表示)
可以使用前幾節提過的基本技巧抓出缺失資料的比例,並繪製成圖
missing_rate = df.isnull().mean().to_frame("rate")
missing_rate = missing_rate[missing_rate.rate!=0].sort_values("rate",ascending=False).transpose()
sns.catplot(kind="bar",data=missing_rate,aspect=2,height=10)
值得一提:
- 這裡使用到mean()對True False視為1,0去平均的特性
- mean()會回傳serial,要用to_frame(“一個標籤名”) 恢復成df
- missing_rate的mask不能寫成一行,否則無法知道rate是誰的標籤
- transpose成 mean對各標籤的表格
- 圖可以藉由height , aspect 操作圖大小
而依照不同缺失比例,可以先取前幾名高比例的index,再利用前面的drop函式進行捨去
也可以替代這些值,
pandas提供了df.fillna()函式來取代這些值
可以做最基本的全部取代成0, 只需要指定0為其參數即可,當然也可以指定其他值 (比如中位數、平均數、或特定字串)
df.fillna(0)
也可以依不同column進行替換,需要以字典參數指定
values = {'index1': 0, 'index2': 1, 'index3': 2, 'index4': 3}
df.fillna(value=values)
還能使用backwordfill , forwardfill 等方式參照前後筆資料決定空值,詳情參考官方文檔
分開數值資料 與 非數值資料
數值資料與非數值資料通常會用不同方式處理
使用第二節提到的df.select_dtypes()來完成
要選取數值資料,可以用df.select_dtypes(include=["number"])
要選取非數值資料,可以用df.select_dtypes(exclude=["number"])
以下使用範例資料集為例,除了提供另一種選取方式,可以更熟悉select_dytpes用法以外,也示範與df.info結合運用
使用df.info()觀察資料型態,可以知道有38個數值資料、43個非數值資料
dtypes: float64(3), int64(35), object(43)
然後使用df.select_dtypes(include=["int64","float64"])來選取所有數值資料
極端值處理
也是一樣先用前面的繪圖方式,印出並觀察SalePrice與數值資料的關係圖
比如下圖
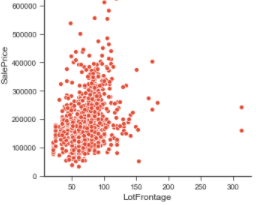
可以快速的了解從訓練資料來看,極端值應該是200
然後就可以用masking技巧刪去極端值,以下是一個例子:
outlier={'LotFrontage':200,'MasVnrArea':1400,'BsmtFinSF1':5000,'TotalBsmtSF':6000,'1stFlrSF':4000, 'GrLivArea':4500,'BedroomAbvGr':8,'TotRmsAbvGrd':14, 'MiscVal':8000]
for index in outlier:
num_data=num_data[ num_data[index] < outlier[index]]
重點統整
-
載入檔案使用
read_csv(<filename>)
輸出檔案使用df.to_csv(<filename>)(json,html也支援對應函式) -
以下能幫助我們快速了解表格
df.info()知道表格意義df.describe()初步了解數值分布df.skew()、df.kurt()可以了解資料imbalance程度、極端值分散程度df.head(n),df.tail(n)選取前後幾列查看例子- 這些函數也是回傳DataFrame,因此能用原表格一樣的方式選取column查看
-
以下兩個方法可以取用特定位置的資料
- DataFrame是key對應到numpy array的dictionary,取用時照該型態邏輯使用即可
特別的是可以用一個list參數指定多column 如 df[[“MSZoning”,“LotFrontage”]] - 也可以使用
loc與iloc屬性
df.loc[起始列數:終止列數 , 起始標籤名:終止標籤名]
df.iloc[起始列數:終止列數 , 起始行數:終止行數]
- DataFrame是key對應到numpy array的dictionary,取用時照該型態邏輯使用即可
-
以下方法能選取特定資料
-
要選取某類型資料,可以用
df.select_dtypes(include=[<your type list>])
要去除某類型資料,可以用df.select_dtypes(exclude=[<your type list>])官方文檔 -
df[判斷邏輯式]即可選取符合判斷式的資料
如df[(df.MSZoning=="RL") | (df.Street == "Pave")] -
df.drop()可以丟掉特定位置資料,給定index list 與 axis 參數即可
axis=0 表示由上而下的操作,所以會刪除橫向的列,axis=1表示由左而右的操作,所以會刪除直向的行 -
整合技巧可以參考其他技巧與整合應用
選出空值資料、選出某行符合某值的所有資料、統計值、排序
-
-
- 使用Seaborn可以很快的搭配pandas進行繪圖
基本格式為sns.relplot(x="特徵名", y="目標名",data=df)此外也有displot(分布圖)與catplot(質性資料圖)等可供使用 - 基本準則如下:
relplot 是數值與數值資料之間使用的,可以看出趨勢、相關性
displot 是數值 或 質性資料 使用的, 可以看出出現次數分布 (所以不用y參數)
catplot 是數值與質性資料之間使用的,可以看出質資料與數值之間關係
- 使用Seaborn可以很快的搭配pandas進行繪圖
-
以下能進行資料前處理
df.fillna()可以用來填補空值,官方文檔- 繪圖搭配mask技巧可以刪去極端資料
- 資料型態選取可以分開數值與屬性資料