原本GAN的問題: JS divergence
JS divergence不適合GAN模型的衡量
因為生成分佈與真實分佈通常兩分佈不會重疊
原因有兩個:
-
data的特性:
生成的目標物通常都只是高維資料中的低維manifold
就像兩條線要在平面中重疊,就算有交點,對平面來說"點"也可以忽略 -
我們有抽樣:
即使兩分佈有overlap,抽樣後也幾乎可以忽略
而JS不適合衡量不重疊的資料,當分佈不重疊,JS總是回傳log2
如下圖
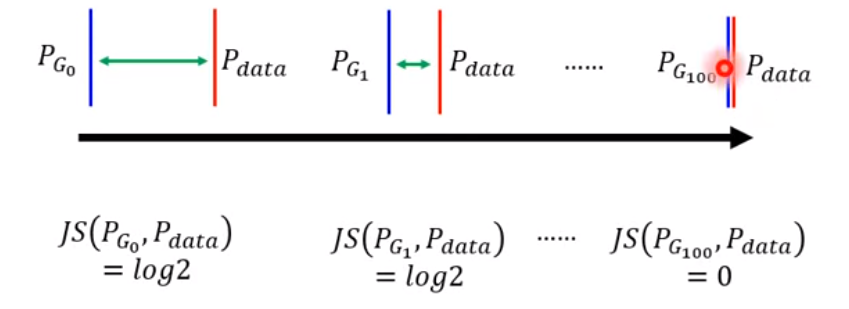
PG0與PG1在JS眼中效果一樣,但顯然PG1比較好
這樣就沒辦法在PG0時更新了
另一直覺: 假如我們discriminator是二分類器
那不管PG0還是PG1,皆能達到100%準度
啟發LS GAN
上述直覺可以用sigmoid圖釋
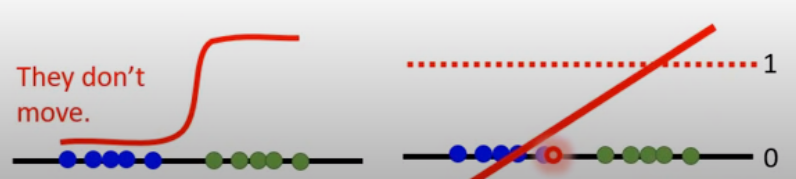
因為區分的太好,導致偏離中間的斜率區
因此有人提出用回歸的方法(Least Square)
假資料低分、真資料高分
然後用回歸線更新,這樣保證斜率存在
Wasserstein GAN (WGAN)
更換 Earth mover`s Distance (Wasserstein distance) 來衡量
解釋
想像自己是一台推土機,要將生成分佈的土推到真分佈所需要的平均距離

問題: 有多種不同鏟法(moving plan)?
窮舉每一種可能,找出最短的平均距離
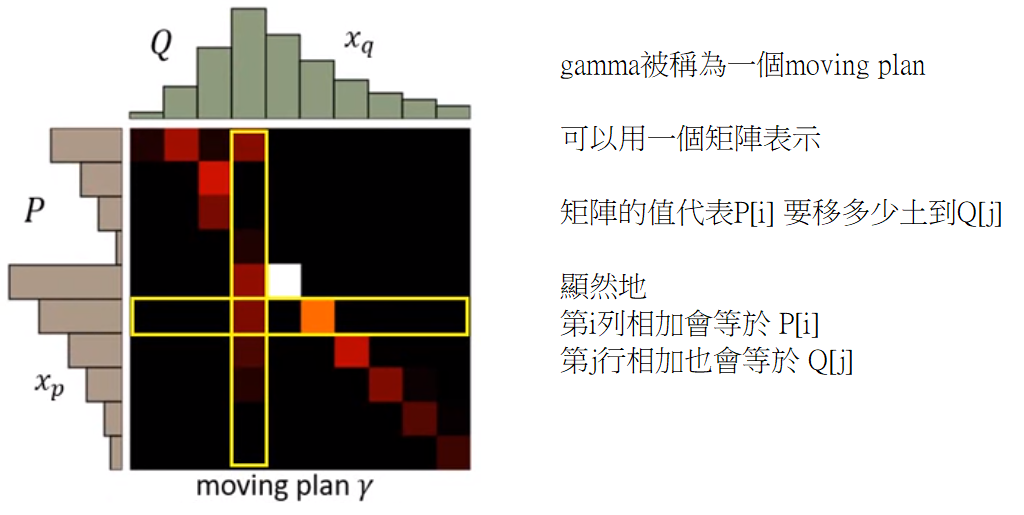
接著講解怎麼衡量moving plan成本

最後Earth mover`s Distance就是最小的moving plan成本
數學式
套用Wasserstein distance的目標函數經過化簡可以得到
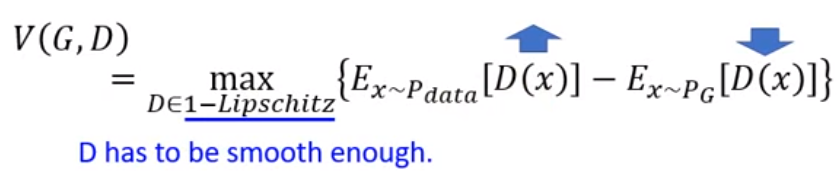
解釋: 在保持D平滑的同時,來自真分佈的評分越高越好,來自生成分佈的評分越低越好
其中 K-Lipschitz 是一種保持函數平滑的限制
|| f(x1) - f(x2) || <= K * ||x1 - x2|| ,其中K==1 就是 1-Lipschitz
解釋: y的變化不能大過x變化的變數
問題怎麼限制1-Lipschitz
照常使用Gradient descent
然後使用Weight clipping
強迫參數要在一個範圍內,如果超出就改成邊界值
比如限制在-10~+10,超過10就設為10
但這其實沒辦法保證1-Lipschitz,只能說是工程的手段去解決
improved WGAN
利用一個數學性質讓目標函數更貼近1-Lipschitz
 白話文就是只要Discriminator是1-Lipschitz
白話文就是只要Discriminator是1-Lipschitz
所有data的gradient就會小於等於1
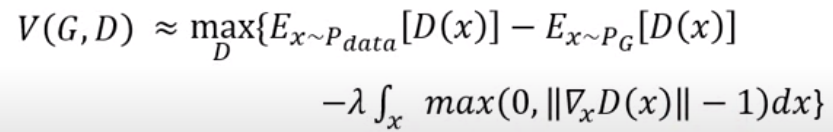
於是有人想到實作上可以加上懲罰項 來讓模型限制在1-Lipschitz
可是由於我們無法算所有data的gradient(無窮個)
因此我們改sample兩個分佈中間的區域
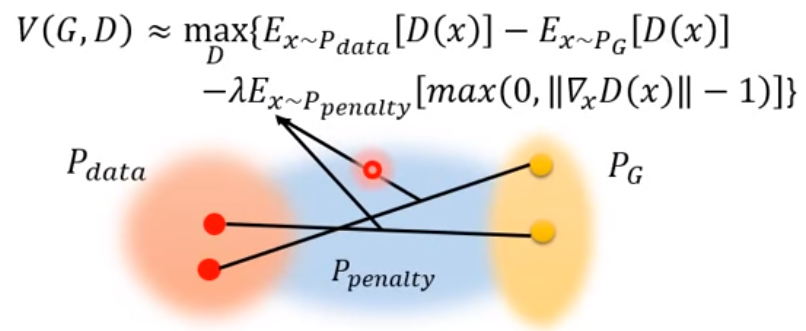
這作法不但實驗上效果好,也符合直覺,因為中間的區域就是模型分佈移動的方向,也是只有這塊區域才會影響結果
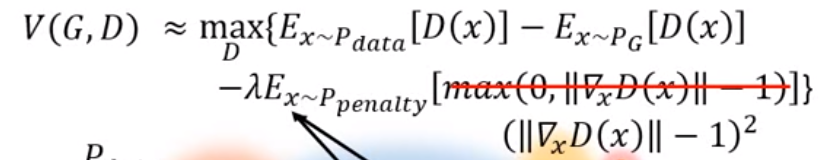
並且實作上會希望gradient越接近1越好 (實驗導向結果)
Energy-based GAN (EBGAN)
使用autoencoder 替代discriminator (不再是二分類器)
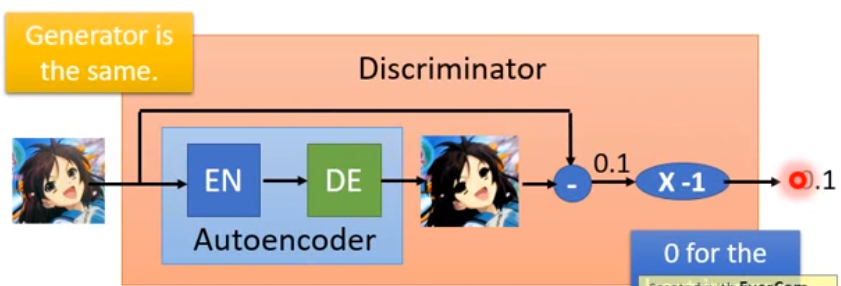
好處: 可以pretrain discriminator