conditional gan (Supervided)
定義
可以藉由輸入可操控的輸入(比如文字)
來得到想要的結果
以下以text to image 解說
test to image
supervised learning
可以用傳統的supervised learning來做
比如為每個image做label,然後學習即可
問題點: 結果通常會模糊,因為模型會回傳不同型態同個物件的平均 (比如火車的正面與側面平均)
Conditional gan
輸入一個文字與隨機vector,產出我們需要的image

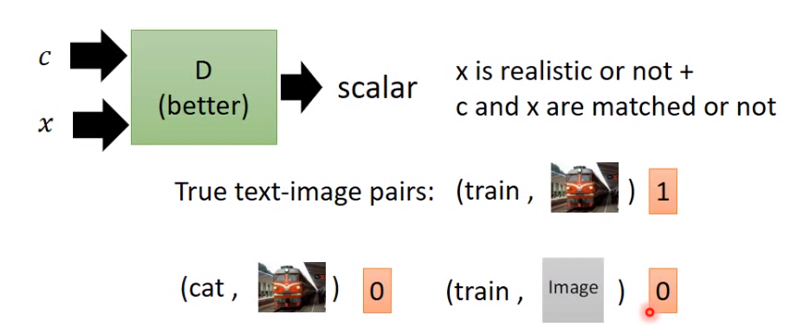
重點是,Discriminator不能按照原本的方式訓練,否則D方會不管輸入文字,只追求高品質
例如,(狗,random vec),但原本訓練的方法會讓高品質的貓也通過
如下圖,還需要要求文字與圖配對正確
演算法

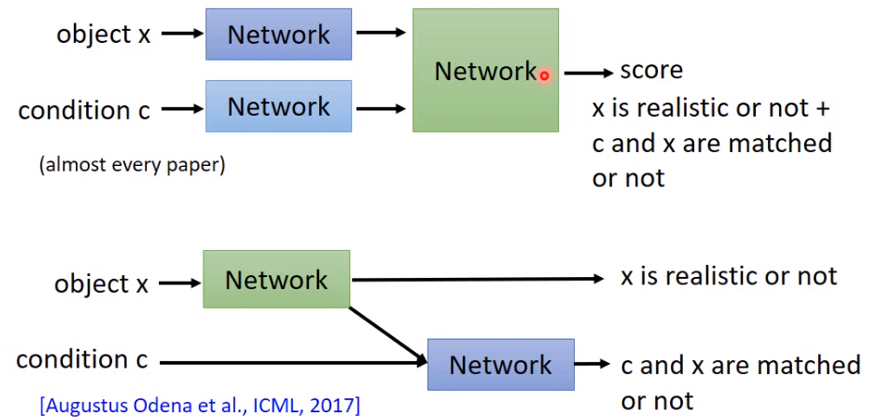
訓練架構下圖比較有潛力
因為兩個Network自己了解為甚麼錯誤
成果示例

有趣的點:
有舉例模仿小精靈的遊戲畫面
用supervised的方式,遇到T型道路時小精靈會分裂
有對抗概念的則可以解決這個問題
Unsupervised Conditional Generation
方法一: 直接轉換(Direct Transformation)
把 Domain X 轉成 Domain Y
通常只能小改,比如顏色、質地
比如畫風轉換
作法
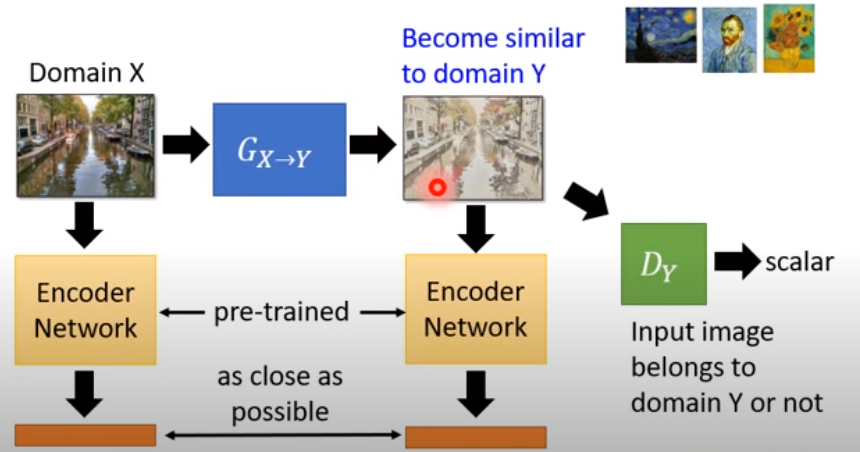
利用特殊領域的Discriminator
比如梵谷畫作鑑別大師
並且還需要X與Y有某種關係
比如輸入風景照片,回傳梵谷自畫像就不會是我們希望的
如何讓X與Y有關係?
- 直接不管這件事 (也可以word,但不好)
- encoder輔助
- CycleGAN
再多訓練一個可以還原的generator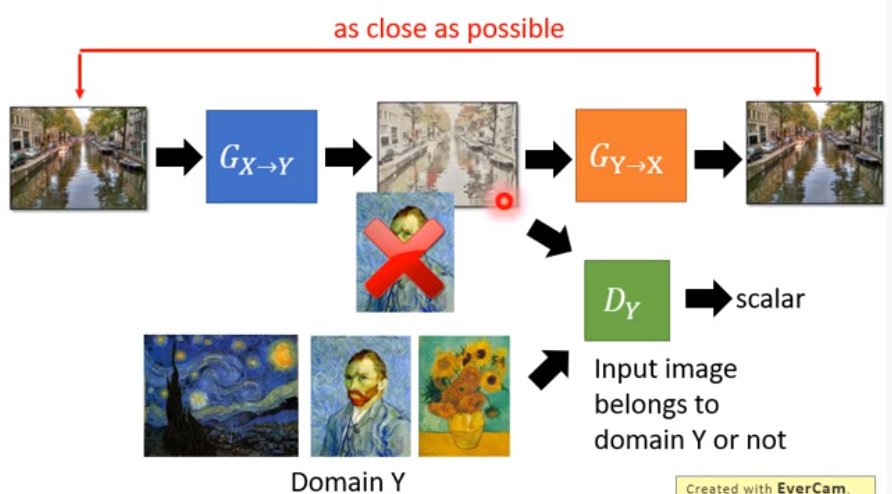
cycleGAN 問題: 隱藏資訊
有可能Gx->y 與 Gy->x之間會用不對的方式隱藏資訊,最後失去CycleGAN的效果
比如
紅螃蟹 => 黑龍蝦 => 紅螃蟹 (為甚麼會知道是紅色?)
- starGAN
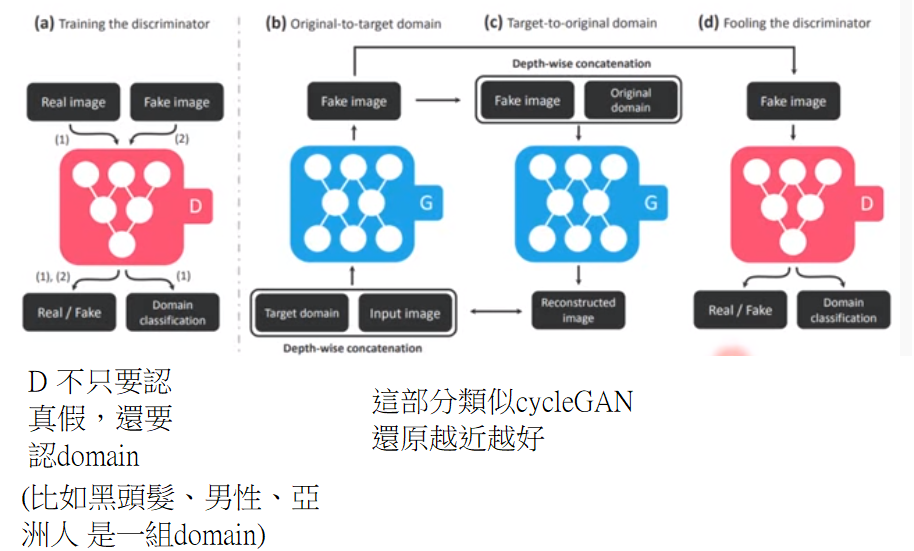
方法二:projection to Common Space
使用encoder , decoder 架構
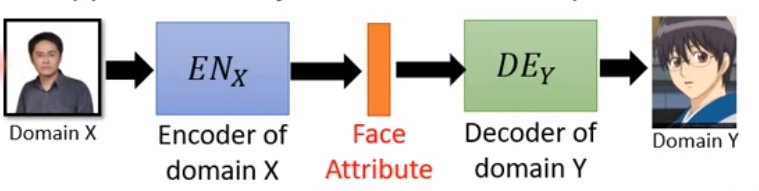
####實作方法
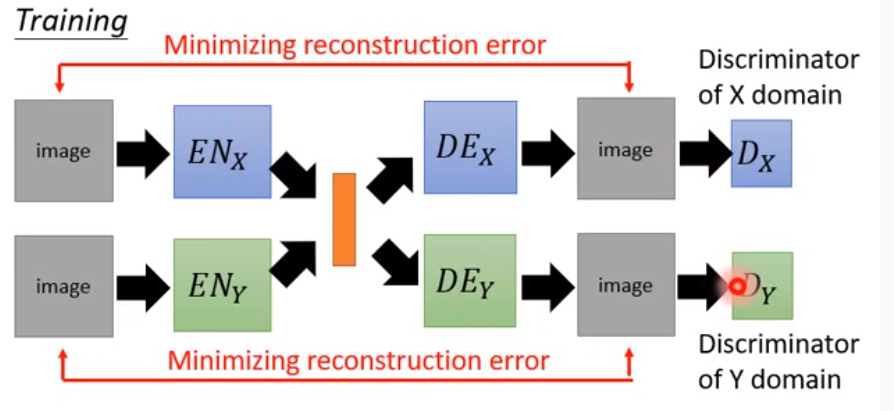 先train X系列、y系列的encoder-decoder
先train X系列、y系列的encoder-decoder
然後再接上Dx、Dy進行判別 (此時兩系列+discriminator是兩條分別的VAEGAN)
但是上下兩的VAEGAN分別訓練,可能導致兩個輸入vector意義不一樣(語言不通,你的第一維是性別,我的可能是年紀)
語言不通解法:
- Couple GAN
離抽象意義屬性的周圍幾層必須是共用的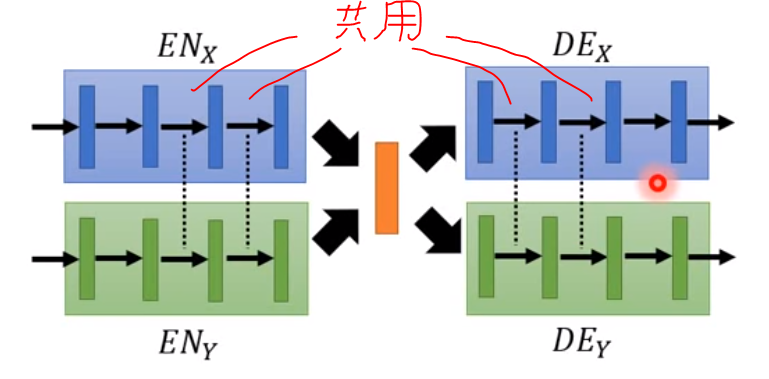
- 加上一個domain disrminator分辨抽象意義屬性的來源
然後想盼法騙過它,使它無法分辨
這時表示兩者語言通了