開場
Yann LeCun 認為GAN技術與其變體非常有趣
而GAN截止2018年已有高達300多種的變體
GAN的論文數在近幾年也暴增
基本概念
Generation
目的在生成東西 (比如圖像、句子、詩文)
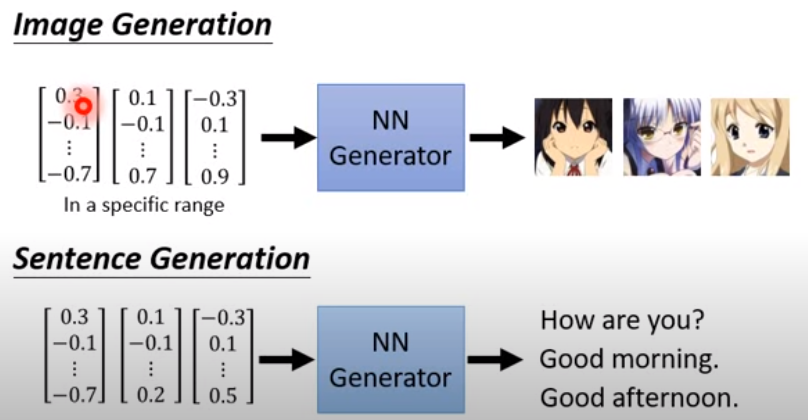
如上圖所示,給定random的向量輸入,輸出不同圖片、句子。
目標就是訓練出NN Generator,並且還希望Generatro是有條件式的生成,輸入有意義、可控制的輸入,得到想要的輸出。
Generator 是甚麼
Generator本質上就是一個Neural network
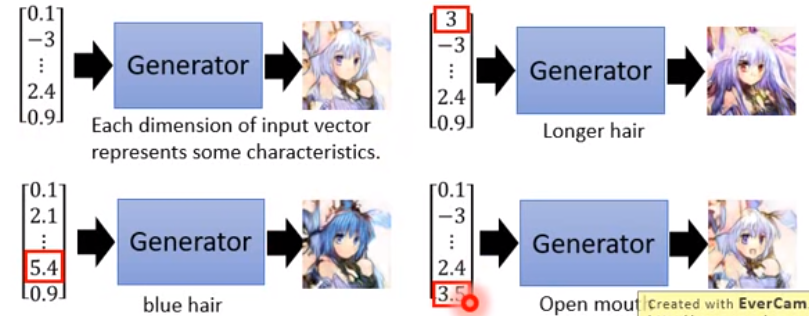
而輸入vecotr會與輸出的高維度向量(目標物)有某種程度的關聯,如下圖
Discriminator
本質上也是一個NN
輸入是一個生成的目標物(比如圖片)
輸出是一個scalar,該值越大表示NN判斷生成物越接近真實
Discriminator 與 Generator就像是生物演化中掠食者與獵物的關係
訓練流程
概念
- 準備一組Real dataset
- 讓Generator NN 生成一組結果
- 讓Discriminator 判斷來自哪裡(Real or Fake)
- 更新兩個NN
這就是Adversarial(對抗)的命名概念
下圖是一個例子
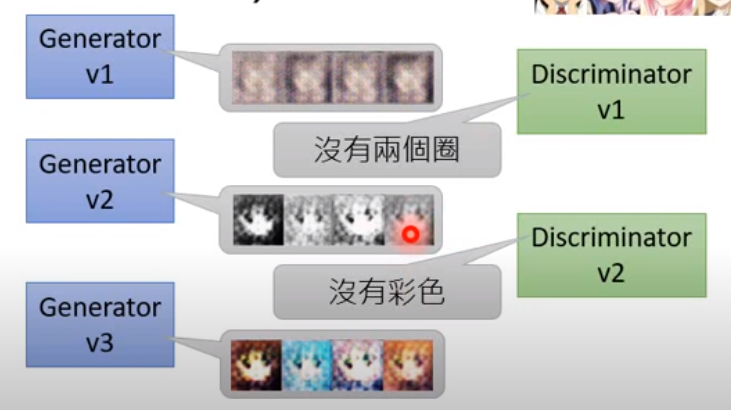
訓練流程演算法 (概念)
Random initialize G and D
for i in iter :
fix G , update D (讓)
fix D , update G
如何更新D?
當作二分類問題處理
首先讓G生成目標物
讓D判斷來自哪裡 (二分類問題)
就可以運用分類/回歸問題的loss function更新方法update D
如何更新G?
** 將G和上一步更新好的D視作一個大NN網路調整**
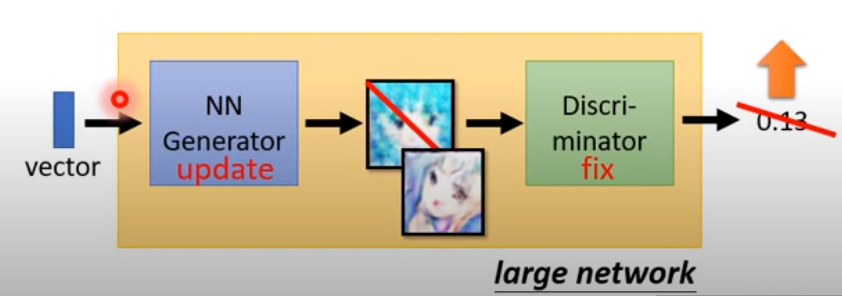
some fact:
- 若G、D各有五層,則這個大網路會有十層
- 中間有一層hidden layer輸出剛好是目標物
- 必須要固定D的layer,否則網路單純的調D最後一層就好
訓練流程演算法 (虛擬碼)

GAN是一種structed learning
Machine learning 目標在找到一個function
Regression 是輸出一個scalar
Classification是輸出一個class
Structed learning/prediction 是輸出一個序列、矩陣、圖、樹…
如下圖

structed learning 挑戰:
-
某個角度是one-shot learning 因為每個training data不太可能會重複(詩文、圖片不太會重複)
因此可能機器會無法真正"創造"新東西 -
機器必須學會規劃(planning),意即體會到元件之間的關系
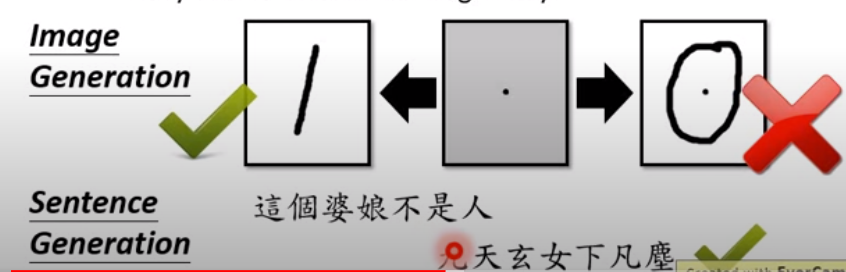
上圖是一個例子,一個點、第一句話都只是一個元件,結果如何取決於元件間的關係
GAN可以說是一個解決方案,他賦予機器大局觀
為甚麼Generator不自己學習?
第一層: 單純訓練
首先這一定是可以做到的,如下圖

問題是輸入怎麼來,如果隨機生成可能造成混亂
比如兩個1的vector長的很不一樣,與我們預期相反
小結: 輸入的隨機性會破壞vector數值的意義
第二層: auto-encoder
更進一步,輸入可以用encoder來解決
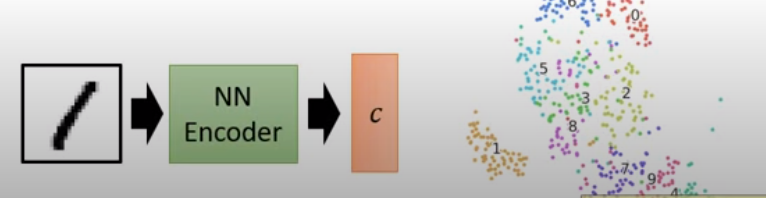
而訓練encoder時就是需要一個decoder(Auto-encoder),這時decoder就類似Generator的角色,encoder就類似Discriminator的角色。
但是auto-encoder並不是線性的,比如頭朝左右,我們會預期0是左,1是右,0.5可能是朝中間這種概念,auto-encoder無法做到
小結: 非線性會讓Vector數值的內插沒有意義
第三層 variational auto-encoder (VAE)
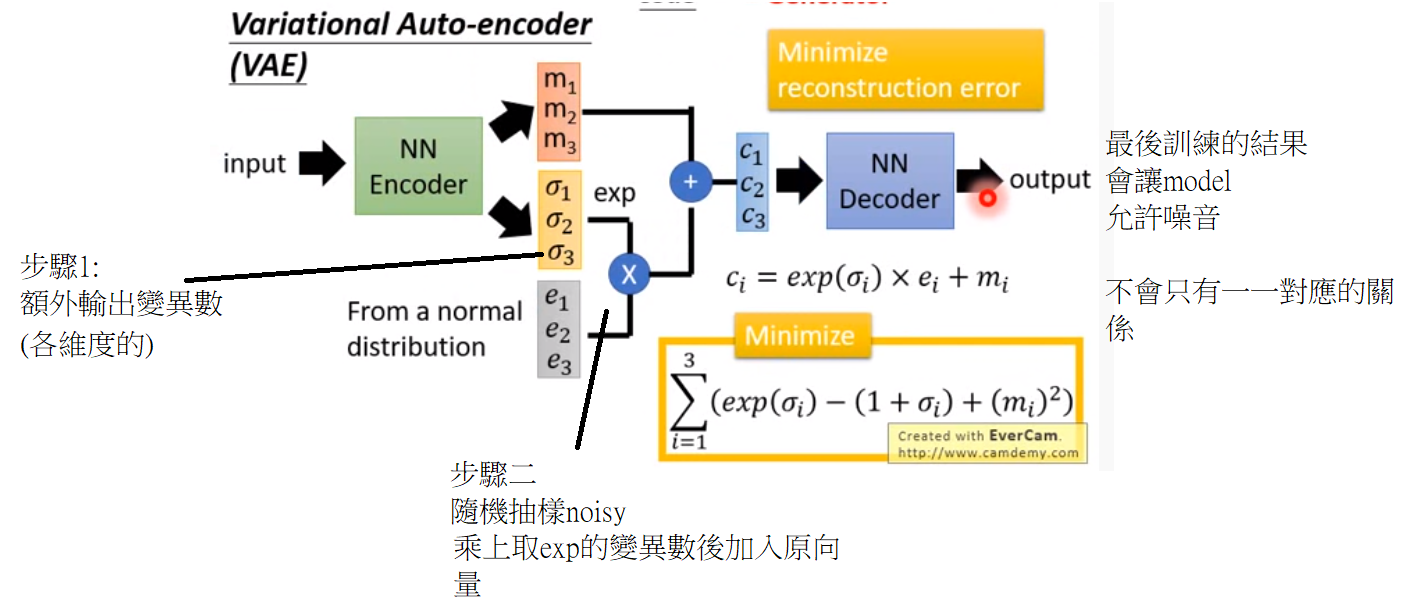
這種作法可以讓加入位移也會生成有意義的東西
Some Fact:
- 增加維度可能會使效能更好,但當維度與data維度一樣,encoder就會學會照抄 (encoder有點像壓縮維度)
- Minimize會追求變異數為0,但我們會阻止便異數太小
但是 ,單純追求loss的縮小(與目標越像越好),會在主觀方面出問題
如下圖

再以下圖舉例
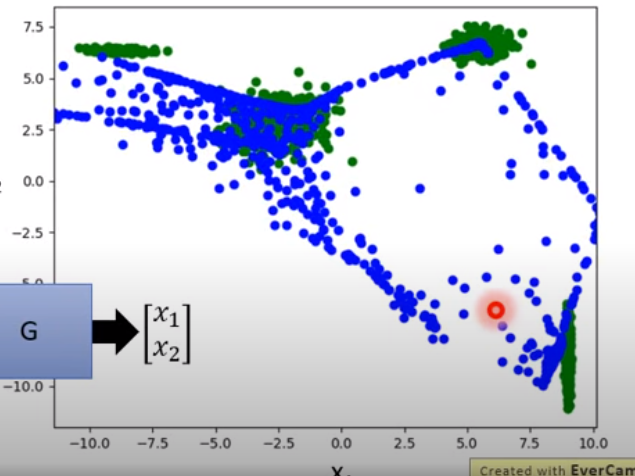
基本上VAE只會學到答案中間的值,並且不會了解到中間某些值可能是不好的。
小結: 單純追求loss減小,會忽略元件之間的關係
總結: 只使用G,會容易變成單純模仿、而忽略大局觀
Discriminator不自己生成?
第一層 直接生成
也是可以實作
窮舉所有x,並找出最大的D(x) (argmax D(x))
問題: 成本過大、並且Discriminator都只接受過高分的例子
第二層 產生好的negative example
可以用隨機的方式
然後類似GAN的方式更新D自己
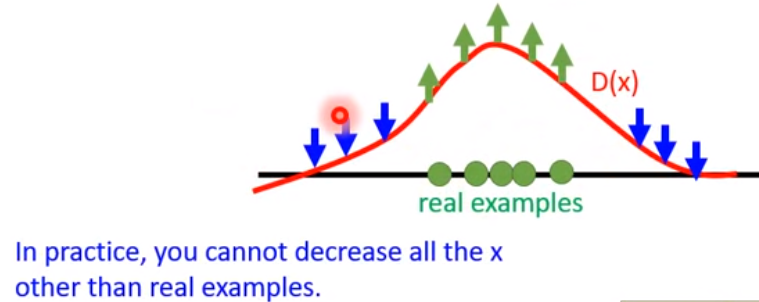
如上圖,這是把高維資料mapping到一維
D(X)紅線是D的判斷給分函數
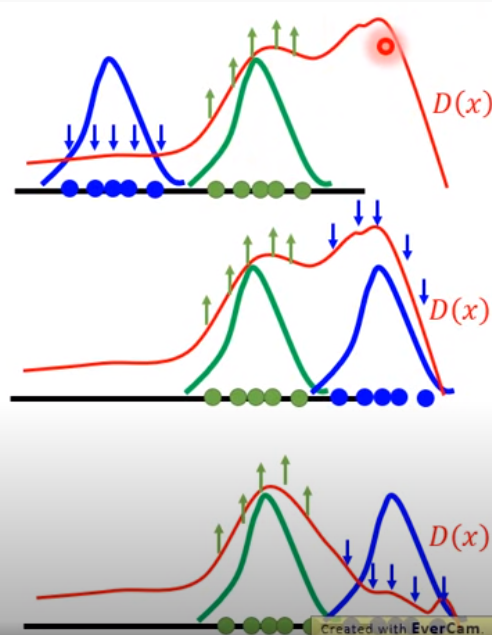
給分=> 窮舉最高點 => 壓低D(X)對fake的地方 …
最終D(x)會與Real data重疊
總結
單純使用 D
- 生成的成本很高(argmax) 甚至非線性解不了
- negative example生成問題
G 正好可以克服這兩個問題(也可以把G當成argmax的解法)
因此GAN是既具有大局觀,又克服生成成本與negative example的方法!
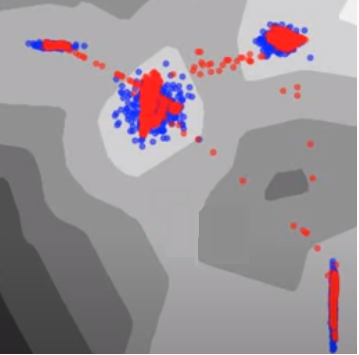
如上圖,GAN不會單純的認為內插值也一定是好的!