imfomation
定義
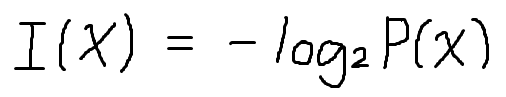
直覺
發生機率越高的事件,資訊含量越低
比如:
豬有四隻腳 VS 有豬在飛
前者不必說,大家都知道(幾乎總是發生,資訊含量小)
後者發生大家都會想看(發生機率小,資訊含量大)
而此數學式則能表達這個直覺,當X事件發生的機率P(X)
很大,取負號後會變很小
由來
imformation最早被應用於資訊領域的編碼問題
而編碼會使用bits為單位,因此會以log2進行計算
而machine learning中最常使用自然對數ln(比如與常態分布掛勾)
可將log2替換為ln (其他底數自然也可以)
Some fact
- 由於0<= P(X) <= 1
這保證了logP(X)是負數,且P(X)越小,logP(X)絕對值越大 - P(x) = 1 , P(x)=0 也符合直覺
- 獨立事件中P(x) = P1(x) * P2(x),而他們的資訊量剛好會變成相加,這也符合直覺
Shannon entropy
定義
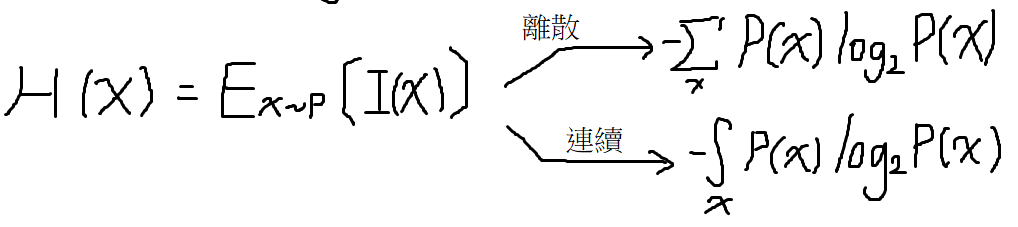
定義為imformation的期待值
代表意義為最少需要多少bit來記錄這段資訊
舉例而言:
假如考過以1紀錄,反之為0
小明考試總是考過,需要多少bit紀錄這個訊息?
代入式子
H(X) = E[I(X)] = 1*-log2(1) = 0
告訴我們不需要紀錄他,畢竟他一定過
小華50%考過,50%考不過,需要多少bit紀錄這個訊息?
代入式子
H(X) = E[I(X)] = 0.5*-log2(0.5)+0.5*-log2(0.5) = 1
告訴我們至少需要準備1bit紀錄這段訊息,因為他是0是1無法預測
這套理論也應用於編碼中用於衡量一個方法的好與壞
Some Fact
Entropy也被稱為亂度,事件發生越平均(越難以預測),比如投公平硬幣,entropy最大
同時也可以以數學證明,Uniform distribution時,entropy最大
Cross Entropy
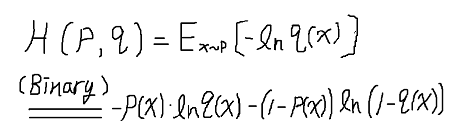
將p(X)視為真實分布(Ground True , 答案y)
q(X)視為模型分布(predict y_hat)
則binary 版本就是二分類中我們熟悉的版本
直覺
H(P,Q)可以視為以P的資料分布,用Q分布方式編碼
所以可以推出
- H(P,Q) 大多不等於 H(Q,P)
- H(P,P) = H(P) 一定是最小值
為甚麼要使用
Cross entropy可以視作p(x)與q(x)的差距
推論:
H(p,p) = H(p)
用同樣編碼、資料
H(p,q) >= H(p,p)
因為H(p)是該分布下最小的編碼成本
H(p,q)不可能比H(p)小
結論: 當Cross Entropy越小,p與q的分布越接近